CSAPP3

本节主要介绍程序的机器级表示,包括数据的表示、指令集架构、汇编语言、以及如何将高级语言转换为机器代码。
程序编码
程序在计算机中是以二进制形式存储和执行的。每条指令和数据都被编码为一系列的0和1,这些二进制数被称为机器码。
使用 Unix 命令行编译这些代码
1 | gcc -Og -o p p1.c p2.c |
-Og 选项启用了一些优化,但仍然保留了调试信息,使得生成的机器代码更接近于源代码的结构。
现在还有一些其他的编译选项可以用来控制优化级别:
-O0:不进行任何优化,生成的代码与源代码结构最接近,适合调试。-O1:进行基本优化,平衡了编译时间和运行-O2:进行更多的优化,通常是默认的优化级别,适合大多数应用。-O3:进行最高级别的优化,可能会增加编译时间和生成的代码大小,但可以提高性能。-Os:优化代码大小,适合内存受限的环境。
程序执行的流程
在研究汇编代码前,需要先对计算机的硬件实现有基本的了解
目前只列出这几个东西:
- 寄存器:包含16个命名的位置,分别存储64位的值。这些寄存器可以存储地址 (对应于C语言的指针)或整数数据。有的寄存器被用来记录某些重要的程序状态,而其 他的寄存器用来保存临时数据,例如过程的参数和局部变量,以及函数的返回值。
- 内存:内存是计算机中用于存储数据和程序的主要组件。内存通常分为主存(RAM)和辅助存储(如硬盘)。
- 程序计数器:给出将要执行的下一条指令在内存中的地址
- 条件吗寄存器:保存着最近执行的算术或逻辑指令的状态信息。它们用来实现控制或数据流中的条件变化,比如说用来实现if和while语句
简单来说,操作系统就是一大个程序,它负责管理计算机的硬件资源,并为其他程序提供运行环境。当我们运行一个程序时,操作系统会将该程序加载到内存中,并分配必要的资源(如CPU时间和内存空间)给它。然后,操作系统会启动程序的执行,并在程序运行过程中进行调度和管理。
当程序加载到内存中时,程序计数器就会来到程序的第一条指令的地址(一般为:0x400000)。CPU 会读取该地址处的指令,并将其解码为一系列的操作。然后,CPU 会执行这些操作,这可能涉及到读取或写入内存、修改寄存器的值、或者与其他硬件组件进行交互。
如果有多个文件,比如 p1.c 和 p2.c,可以使用以下命令将它们一起编译成一个可执行文件 p:
1 | gcc -Og -o p p1.c p2.c |
如果要生成汇编代码,可以使用 -S 选项:
1 | gcc -Og -S -o p1.s p1.c |
多个文件一起编译时,使用了链接器(linker)来将各个目标文件(object files)合并成一个可执行文件。链接器会处理函数调用和变量引用,确保所有的符号都能正确地解析。在第七章中会详细介绍链接器的工作原理。
数据格式
发展过程中,计算机是从16位发展到32位,再到64位的。每个数据单元的大小通常是8位(1字节),16位(2字节),32位(4字节),或64位(8字节)。在64位计算机中,寄存器和内存地址通常是64位的。
| C声明 | Intel 数据类型 | 汇编代码后缀 | 字节 |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
| char * | 四字 | q | 8 |
寄存器
上面介绍了寄存器,在64位的 x86-64 架构中,有16个通用寄存器:
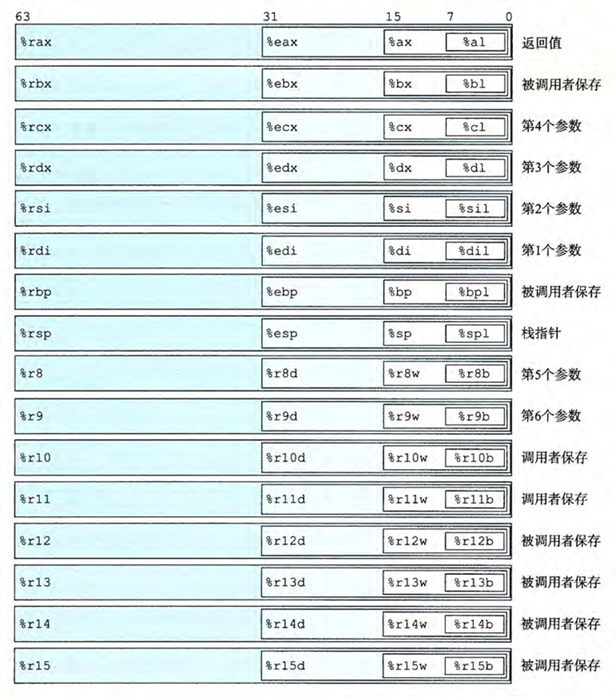
可以看到,寄存器有四字的(32位),双字的(16位),和字节的(8位)表示形式。例如,寄存器 rax 的低32位可以通过 eax 访问,低16位可以通过 ax 访问,而低8位可以通过 al 访问。
并且各自的作用不同,后面叙述汇编时会解释它们的作用
还有一个特殊的寄存器 rip,它是程序计数器,指向下一条要执行的指令的地址
操作数
操作数是指令中用于指定数据的位置或值的部分。操作数可以是寄存器、内存地址、立即数(常数值)等。
对于某个操作,可以储存在寄存器中,也可以储存在内存中,也可以是一个立即数。
格式如下:
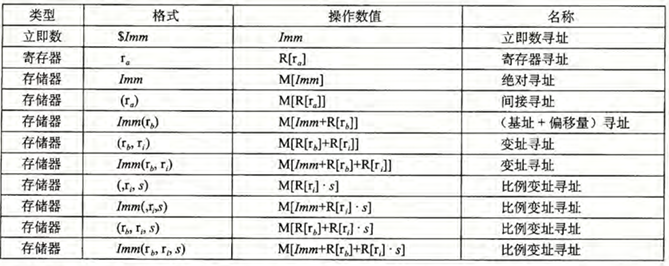
汇编指令
数据传送指令
这是一个从一个位置复制到另一个位置的指令
mov
根据目的类型不同,可以分为下面几类
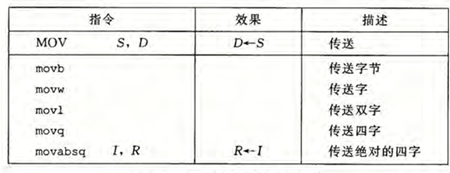
mov 指令的格式是
1 | mov S,D |
其中 S 是源地址,D 是目的地址
根据操作的操作数不同,一共有 5 种组合
Imm - Reg
Reg - Reg
Mem - Reg
Reg - Mem
Imm - Mem
考虑下面这段汇编
1 | movabsq $0x11223344556677, %rax #%rax = 0x0011223344556677 |
也就是说,movl 有个特点:它会将寄存器的高32位置零
movz
这是一个实现零扩展的指令

打个比方:
1 | movzbq %al, %rax |
这里假设 %al 的值是 0xFF(8位),那么执行这条指令后,%rax 的值将变成 0x00000000000000FF(64位)。也就是说,%al 的值被复制到了 rax 的低8位,而高56位被填充为0。
movs
这是一个实现符号扩展的指令
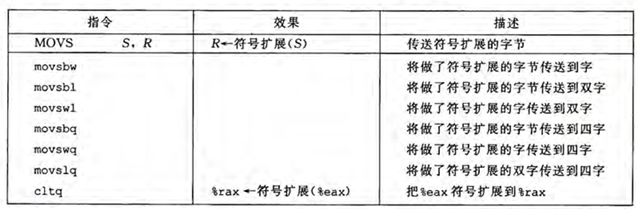
打个比方
1 | movsbq %al, %rax |
这里假设 %al 的值是 0xFF(8位),那么执行这条指令后,%rax 的值将变成 0xFFFFFFFFFFFFFFFF(64位)。也就是说,%al 的值被复制到了 rax 的低8位,而高56位被填充为符号位(即最高位的值)。
考虑下面这段汇编
1 | movabsq $0x0011223344556677,%rax #%rax = 0x0011223344556677 |
这清晰的展示了 movsbq 和 movzbq 的区别:前者进行符号扩展,后者进行零扩展。
练习题 3.3 当我们调用汇编器的时候,下面代码的每一行都会产生一个错误消息。解释每一行都是哪里出了错。
movb $0xF, (%ebx) 错误:在 64 位架构中,内存寻址必须使用 64 位寄存器。此处不能使用 32 位寄存器 %ebx 作为地址,应改为 %rbx。
movl %rax, (%rsp) 错误:指令后缀 ‘l’ 表示 32 位操作,但操作数 %rax 是 64 位寄存器。指令后缀与寄存器大小不匹配。
movw (%rax),4(%rsp) 错误:mov 指令不能同时将两个操作数(源和目的)都设为内存引用。
movb %al,%sl 错误:不存在名为 %sl 的寄存器。%rsi 的低 8 位寄存器名称应为 %sil。
movq %rax,$0x123 错误:mov 指令的目的操作数不能是立即数。
movl %eax,%rdx 错误:指令后缀 ‘l’ 表示 32 位操作,但目的操作数 %rdx 是 64 位寄存器。指令后缀与寄存器大小不匹配。
movb %si, 8(%rbp) 错误:指令后缀 ‘b’ 表示 1 字节(8 位)操作,但 %si 是 2 字节(16 位)寄存器。指令后缀与寄存器大小不匹配。
程序栈和相关指令
栈是内存中的一个特殊区域,在处理程序过程中有重要作用
程序栈的实现使用了一个寄存器指针 rsp(栈指针寄存器),它指向栈顶的位置。栈通常从高地址向低地址增长,这意味着每次向栈中压入数据时,rsp 的值会减少,而弹出数据时,rsp 的值会增加。

push
功能是把数据压人到栈上
比如 pushq %rbp 等价于下面的汇编
1 | subq $8 %rsp #栈指针减8,给新数据腾出空间 |
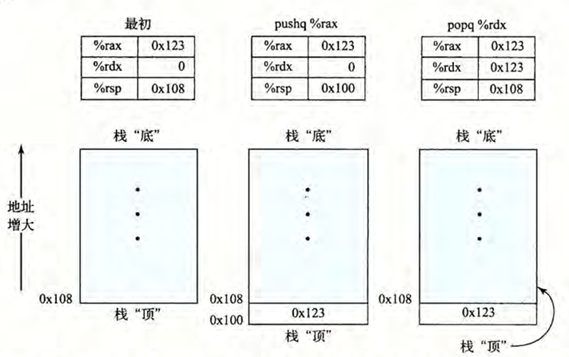
pop
功能是把数据从栈上弹出
比如 popq %rbp 等价于下面的汇编
1 | movq (%rsp), %rbp #把栈顶的数据存到rbp |
算术和逻辑指令
分为四组:
加载有效地址、一元操作、二元操作和移位
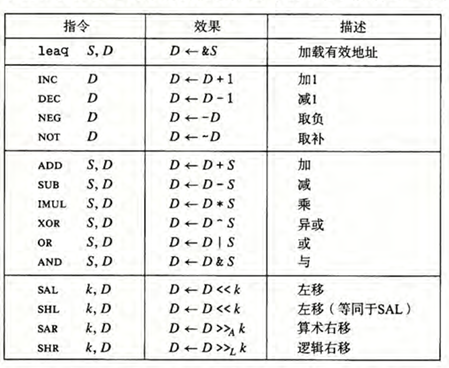
加载有效地址
leaq 指令用于计算内存地址,并将结果存储在寄存器中。它的语法为 leaq S,D
lea 实际上是 mov 的变形,从内存读数据到寄存器,但根本没有引用内存
第一个数据看上去是内存引用,但实际上是一个地址计算表达式
这个指令只能用于计算地址,不能用于访问内存中的数据,然后放在寄存器中
1 | long scale(long x, long y, long z){ |
编译时,都采用 leaq 实现
1 | scale: |
练习 3.7
1 | long scale2(long x, long y, long z){ |
一元和二元操作
一元操作只涉及一个操作数,二元操作涉及两个操作数
一元操作的操作数即是源又是目的,操作数可以是寄存器或内存地址
比如 negq %rax 将寄存器 rax 的值取反,并将结果存储回寄存器 rax 中。
二元操作有两个操作数,源和目的,目的操作数既是输入又是输出
第一个操作数可以是立即数、寄存器或内存地址,第二个操作数可以是寄存器或内存地址
例如,指令 subq %rax,%rdx使寄存器rdx的值减去寄存器rax的值,并将结果存储回寄存器rdx中。
移位操作
移位操作用于将二进制数的位向左或向右移动。常见的移位指令包括:
shl(逻辑左移):将操作数的位向左移动,右侧补零。shr(逻辑右移):将操作数的位向右移动,左侧补零。sar(算术右移):将操作数的位向右移动,左侧补符号位(即最高位的值)。
第一个操作数可以是立即数、寄存器或内存地址,第二个操作数可以是寄存器或内存地址
需要注意的是第一个操作数如果存放在寄存器中,一定是在 %cl 中的
移位操作对 \(w\) 位长的数据值进行操作,移位量是由 %cl 寄存器的低 \(log_2 w\) 位给出的,高位会被忽略
这段话的核心意思翻译成数学语言就是:移位量 \(k\) 实际上等于 %cl 寄存器中的值对数据位宽 \(w\) 取模的结果。
\[k = \text{寄存器值} \pmod w\]
移位操作是针对位宽为 \(w\) 的数据进行的。如果移位量等于或超过了 \(w\),那么所有的位都会被移出(结果全为 0 或全为符号位),这在绝大多数硬件实现中被认为是无意义的。
因此,硬件只选取 %cl 寄存器中能够表达 \(0\) 到 \(w-1\) 范围的那些低位: * 如果是 32 位数据 (\(w=32\)): * \(log_2 32 = 5\)。 * 硬件只看 %cl 的低 5 位(范围是 \(0 \sim 31\))。 * 即便你在 %cl 里写了 32(二进制 100000),硬件只看低 5 位(即 00000),实际移位量是 0。 * 如果是 64 位数据 (\(w=64\)): * \(log_2 64 = 6\)。 * 硬件只看 %cl 的低 6 位(范围是 \(0 \sim 63\))。 * 即便你在 %cl 里写了 65(二进制 1000001),硬件只看低 6 位(即 000001),实际移位量是 1。
假设我们要对一个 32 位的整数进行左移操作,此时 %cl 寄存器的值设为 0xFF(十进制 255,二进制 1111 1111):
- 确定位宽 \(w\):32 位。
- 确定掩码位数:\(log_2 32 = 5\) 位。
- 提取低位:
0xFF的二进制后 5 位是11111(十进制 31)。 - 实际操作:硬件执行的是“左移 31 位”,而不是“左移 255 位”。
练习题 3.10
1 | long arith2(long x, long y, long z){ |
练习题 3.11
常常可以看见以下形式的汇编代码行:
1 | xorq %rdx, %rdx |
但是在产生这段汇编代码的C代码中,并没有出现EXCLUSIVE-OR操作
A.解释这条特殊的 EXCLUSIVE-OR 指令的效果,它实现了什么有用的操作。
B. 更直接地表达这个操作的汇编代码是什么?
C。比较同样一个操作的两种不同实现的编码字节长度。
A. 这条指令的效果是将寄存器 %rdx 的值设置为 0。由于任何数值与其自身进行异
或(EXCLUSIVE-OR)运算的结果总是 0,因此这条指令实现了一个非常有用的操作:将寄存器清零。
B. 更直接地表达这个操作的汇编代码是使用传送指令:movq $0, %rdx。
C. 比较两种实现的编码字节长度: - xorq %rdx, %rdx 的指令编码通常只需要 3 个字节。 - movq $0, %rdx 的指令编码通常需要 7 个字节(因为需要空间来编码立即数 0)。 在实际应用中,编译器经常使用 32 位版本的 xorl %edx, %edx,它只需要 2 个字节,且根据 x86-64 规则,对低 32 位寄存器的写操作会自动将高 32 位清零。总的来说,使用异或指令比使用传送指令更节省空间。
特殊算术操作

imulq 和 mulq
虽然前面提到的 imulq 可以作为二元操作(产生 64 位乘积并截断),但在处理两个 64 位有符号或无符号数产生完整 128 位乘积时,需要使用单操作数形式。
imulq S:有符号全乘法。mulq S:无符号全乘法。
这两条指令都要求一个参数必须在寄存器 %rax 中,另一个参数作为指令的源操作数 S 给出。乘法的结果(128 位)存储在两个寄存器中:高 64 位存储在 %rdx 中,低 64 位存储在 %rax 中。
1 |
|
1 | # x 在 %rsi, y 在 %rdx, dest 在 %rdi |
clto
clto 指令不带任何操作数。它的作用是将寄存器 %rax 中的 64 位值有符号地扩展到 128 位。
- 具体操作是将
%rax的符号位(最高位)复制到寄存器%rdx的所有位中。 - 这通常是为了准备进行有符号除法,将
%rdx:%rax形成一个完整的 128 位被除数。
idiv 和 divq
除法指令用于处理 128 位被除数。
idivq S:有符号除法。divq S:无符号除法。
操作流程如下:
- 被除数:存储在
%rdx(高 64 位)和%rax(低 64 位)构成的 128 位值中。 - 除数:由指令的操作数
S给出。 - 结果:商存储在寄存器
%rax中,余数存储在寄存器%rdx中。
对于有符号除法,在调用 idivq 之前,通常先使用 clto 指令将被除数从 64 位扩展到 128 位。对于无符号除法,通常需要先手动将 %rdx 清零(例如使用 xorl %edx, %edx)。
1 | void remdiv(long x, long y, long *qp, long *rp) { |
1 | # x 在 %rdi, y 在 %rsi, qp 在 %rdx, rp 在 %rcx |
无符号:
1 | void uremdiv(unsigned long x, unsigned long y, |
1 | # x 在 %rdi, y 在 %rsi, qp 在 %rdx, rp 在 %rcx |
控制
上述都是直线代码的指令,也就是顺序指令,但是 C 中存在条件语句、循环语句和分支语句,也就是说,程序的控制流并不是直线的
所以需要一些控制指令来实现这些功能
条件码
条件码寄存器包含了一组标志位,这些标志位反映了最近执行的算术或逻辑指令的结果状态。常见的条件码包括:
CF:进位标志。最近的操作使最高位产生了进位。可用来检査无符号操作的溢出ZF:零标志。最近的操作结果为零。SF:符号标志。最近的操作结果为负数(最高位为1)OF:溢出标志。最近的操作导致补码正溢出或负溢出
这些条件码实际上是在算术和逻辑指令执行后自动设置的,程序员可以通过条件跳转指令来检查这些标志位,从而实现条件控制流。
也就是比如数字逻辑实现的加法器的一个输出
可以根据下面的 C 表达式设置条件码
比如使用 addq a, b 指令后,可以根据结果 t = a + b 来设置条件码:
| 条件码 | C 表达式 | 描述 |
|---|---|---|
| CF | (unsigned) t < (unsigned) a | 无符号溢出 |
| ZF | (t == 0) | 零 |
| SF | (t < 0) | 负数 |
| OF | (a < 0 == b < 0) && (t < 0 != a < 0) | 有符号溢出 |
leaq 不会改变条件码,因为它不执行实际的算术运算,只是计算地址。
除此之外,其他所有的算术和逻辑指令都会根据结果设置条件码。
对于移位操作,进位标志将设置为最后一个被移出的位,而溢出标志设置为0。
INC 和 DEC指令会设置溢出和零标志,但是不会改变进位标志
cmp 和 test
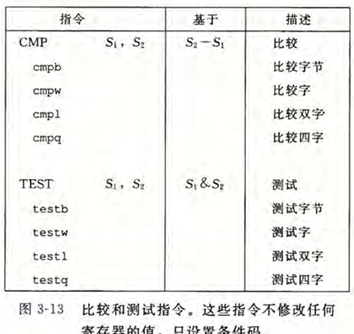
cmp 和 test 指令用于比较两个操作数,并根据比较结果设置条件码
cmp S1, S2:比较S2 - S1,并设置条件码。test S1, S2:对S1和S2进行按位与操作,并设置条件码。
它们不改变目的寄存器的值,只是影响条件码
比如 testq %rax, %rax 实际上是在检查 %rax 是否为零,
因为按位与操作会将 %rax 的值与自身进行比较
如果 %rax 为零,结果也为零,设置零标志 ZF;如果 %rax 非零,结果非零,清除零标志 ZF
访问条件码

无符号辅助记忆:a是大于,b是小于
条件码通常不会直接读取,常用的使用方法有三种:
可以根据条件码的某种组合, 将一个字节设置为0或者1
可以条件跳转到程序的某个其他的部分
可以有条件地传送数据
一条SET指令的目的操作数是低位单字节寄存器元素之一,或是一个字节的内存位置,指令会将这个字节设置成0或者1
1 | #x在%rdi, y在%rsi |
cmpq 的作用是计算 rdi - rsi,并根据结果设置条件码,注意比较顺序
某些底层的机器指令可能有多个名字,我们称之为“同义名(synonym)”。比如说, setg(表示“设置大于”)和 setnle(表示“设置不小于等于”)指的就是同一条机器指令。 编译器和反汇编器会随意决定使用哪个名字
练习题 3.13
data_t 是 int,COMP 是 \(<\)
data_t 是 short,COMP 是 \(\ge\)
data_t 是 unsigned char,COMP 是 \(\le\)
data_t 是 long,COMP 是 \(!=\)
练习题 3.14
data_t 是 long,TEST 是 \(\ge\)
data_t 是 short,TEST 是 \(==\)
data_t 是 unsigned char,TEST 是 \(>\)
data_t 是 int,TEST 是 \(!=\)
跳转指令
jump 导致程序执行切换到另一个位置
可以是直接跳转,即跳转目标是作为指令的一部分编码的;
也可以是间接跳转,即跳转目标是从寄存器或内存位置中读出的
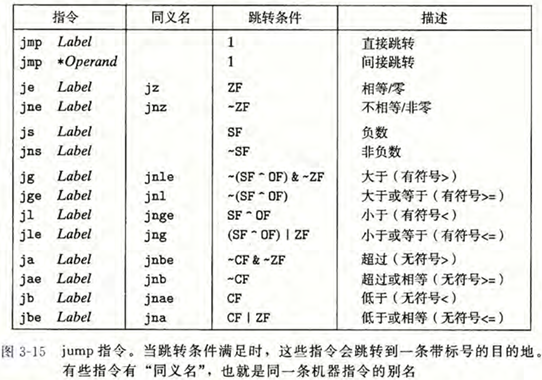
跳转指令有几种不同的编码,但是最常用都是PC相对的(PC-relative)
它们会将目标指令的地址与紧跟在跳转指令后面那条指令的地址之间的差作为编码。这些地址偏移量可以编码为1、2或4个字节,这个字节使用的是补码
第二种编码方法是给出“绝对”地址,用4个字节直接指定目标。 汇编器和链接器会选择适当的跳转目的编码。
练习题 3.15
目标地址 是 0x4003fe
目标地址 是 0x400425
ja 地址是 0x400543
目标地址 是 0x400560
条件分支的实现
条件控制实现
实现条件操作的传统方法是通过使用控制的条件转移
如下面这个C 函数
1 | long lt_cnt = 0; |
他在汇编中类似下面的goto版本:
1 | long gotodiff_se(long x, long y){ |
也就是下面这个:
1 | absdiff_se: |
这完整解释了整个翻译过程,通用模板如下:
1 | if (test-expr) |
1 | t = test-expr; |
也就是,汇编器为 then-statement 和 else-statement 产生各自的代码块。它会插人条件和无条件分支,以保证能执行正确的代码块
练习 3.16
1 | void cond_goto(long a, long *p) { |
这是因为 C 语言中逻辑与运算符 && 的短路求值(short-circuit evaluation)特性 在表达式 p && a > *p 中,如果第一个条件 p 为假(即 p 为空指针),则整个表达式的结果已确定为假,程序必须不能计算第二个条件 a > *p,因为对空指针进行解引用(*p)会导致内存访问错误(段错误) 为了实现这种逻辑,编译器生成的汇编代码会将该复合条件拆分为两个独立的测试:第一个测试检查指针是否有效,只有在有效的情况下,才会执行第二个涉及解引用的测试
练习 3.17
另一种翻译如下:
1 | t = test-expr; |
1 | absdiff_se(long x, long y){ |
练习 3.18
1 | long test(long x, long y, long z){ |
条件传送实现
一种替代的策略是使用数据的条件转移
计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个
只有在一些受限制的情况中,这种策略才可行,但是如果可行,就可以用一条简单的条件传送指令来实现它
1 | long absdiff(long x, long y){ |
翻译为相同的 goto 形式
1 | long cmvdiff(long x, long y){ |
汇编如下:
1 | cmvdiff: |
处理器通过使用流水线(pipelining)来获得高性能,在流水线中,一条指令的处理要经过一系列的阶段,每个阶段执行所操作的一小部分
通过重叠指令的方式来获取了高性能
在取一条指令的同时,执行它前面一条指令的算术运算。要做到这一点,要求能够事先确定要执行的指令序列,这 样才能保持流水线中充满了待执行的指令。当机器遇到条件跳转(也称为“分支”)时,只 有当分支条件求值完成之后,才能决定分支往哪边走
另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后所有指令已做的工作,然后再开始用从正确位置处起始的指令去填充流水线。正如我们会看到的,这样一个错误预测会招致很严重的惩罚,浪费大约15到30个时钟周期,导致程序性能严重下降
分支预测错误处罚主导着这个函数的性能
设预测错误概率为 \(p\)
如果没有预测错误,执行代码时间为 \(T_{OK}\),预测错误惩罚 为 \(T_{MP}\)
执行代码的平均时间为 \(T_{arg}(p)=(1-p)T_{OK}+p(T_{MP}+T_{OK})=T_{OK}+pT_{MP}\)
练习 3.19
A. \(T_{random} = T_{OK} + 0.5 * T_{MP}=31\)
解得 预测错误约为 30 个时钟周期
B. 预测错误时,需要 46 个时钟周期
cmov
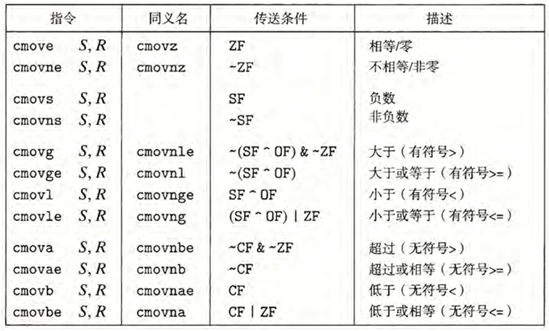
这个指令结果取决于条件码的值。源值可以从内存或者源寄存器中读取
同条件跳转不同,处理器无需预测测试的结果就可以执行条件传送。处理器只是读源值(可能是从内存中),检查条件码,然后要么更新目的寄存器,要么保持不变。
的最后一条语句是用条件传送实现的—— 只有当测试条件t满足时,vt的值才会被复制到v中
不是所有的条件表达式都可以用条件传送来编译
根据经验,即使许多分支预测错误的开销会超过更复杂的计算,GCC还是会使用条件控制转移
练习 3.20
A. OP 进行除法
B
1 | arith: |
这是有符号数除以 2 的幂的典型实现。为了实现向零舍入,当 x 为负数时需要加上一个偏移量(bias = 2^k - 1),这里 k=3,所以偏移量是 7。如果 x 为正,则不加偏移量
练习 3.21
1 | long test(long x, long y){ |
switch 语句
可以根据一个整数索引值进行多重分支
不仅提高了C代码的可读性,而且通过使用跳转表(jump table)这种数据结构使得实现更加高效
使用跳转表的优点是执行开关语句的时间与开关情况的数量无关
GCC根据开关情况的数量和开关情况值的稀疏程度来翻译开关语句
当开关情况数量比较多(例如4个以上),并且值的范围跨度比较小时,就会使用跳转表
switch 进行了下面几个过程
- 偏移量处理:如果 case 的值不是从 0 开始(例如是 100, 101…),编译器会先减去最小值,使索引范围从 0 开始。
- 边界检查:使用一个无符号比较(cmp 和 ja)来检查索引是否超出了跳转表的范围。如果超出,则直接跳转到 default 分支。
- 间接跳转:通过跳转表进行索引并跳转。
比如下面这个
1 | void switch_eg(long x, long n, long *dest) |
翻译为类似汇编就是
1 | void switch_eg_impl(long x, long n, long *dest) |
可以看到编译器为 switch 语句生成了一个跳转表 jt
这个 jt 的大小和 case 的范围有关
然后先对 n 进行偏移量处理,计算出索引 index
然后检查 index 是否在跳转表范围内
如果超出范围,跳转到 default 分支
否则通过跳转表进行间接跳转
如果 case 的范围很大,但是 case 的数量很少,编译器就不会使用跳转表,而是使用一系列的条件跳转来实现 switch 语句
练习 3.30
根据汇编代码分析:
- 偏移量处理:第一行指令
addq $1, %rdi将输入变量x加 1。设调整后的值为 \(x' = x + 1\)。 - 边界检查:指令
cmpq $8, %rdi和ja .L2表明,如果 \(x'\) 大于 8(无符号比较),则跳转到标号.L2(即default分支)。这意味着有效的索引范围是 \(0 \le x' \le 8\)。 - 计算原始标号值:对应 \(x'\) 的索引值 \(0, 1, 2, 3, 4, 5, 6, 7, 8\),原始的
x值(即 C 代码中的标号)分别为 \(-1, 0, 1, 2, 3, 4, 5, 6, 7\)。 - 识别有效标号:观察跳转表
.L4,凡是指向非默认标号(非.L2)的索引对应的x值即为情况标号:- 索引 0 (\(x = -1\)): 指向
.L9 - 索引 1 (\(x = 0\)): 指向
.L5 - 索引 2 (\(x = 1\)): 指向
.L6 - 索引 3 (\(x = 2\)): 指向
.L7 - 索引 4 (\(x = 3\)): 指向
.L2(默认/缺失) - 索引 5 (\(x = 4\)): 指向
.L7 - 索引 6 (\(x = 5\)): 指向
.L8 - 索引 7 (\(x = 6\)): 指向
.L2(默认/缺失) - 索引 8 (\(x = 7\)): 指向
.L5
- 索引 0 (\(x = -1\)): 指向
因此,情况标号的值分别为:-1, 0, 1, 2, 4, 5, 7
通过观察跳转表中的重复目标地址(排除 .L2):
- 标号 0 和 7:它们在跳转表中都指向
.L5。 - 标号 2 和 4:它们在跳转表中都指向
.L7。
注:标号 3 和 6 指向 .L2,通常表示这两个值在 C 代码中没有对应的 case 标签,从而落入了 default 分支。
练习 3.31
1 | void switcher(long a, long b, long c, long *dest){ |
循环分支的实现
do-while 循环
是最简单的循环结构,循环体至少执行一次
1 | long pcount_do(unsigned long x) { |
对应 goto 形式
1 | long pcount_do_goto(unsigned long x) { |
通用模板
1 | loop: |
3.23
rax 存放x,rcx存放y,rdx 存放n
编译器观察到指针 p 指向局部变量 x,因此 (*p)++ 实际上就是 x++。在循环体中,原本有 x += y 和 (*p)++ 两个操作,编译器将它们合并为 x = x + y + 1。通过将 x 存储在寄存器 %rax 中,编译器可以使用一条 leaq 指令直接完成这两个操作,从而消除了对内存的间接引用
while 循环
中间跳转法
通过一条无条件跳转指令进入循环末尾的测试部分
1 | goto test; |
Guarded-do 形式
首先用一个 if 语句测试初始条件,如果成立则进入一个 do-while 循环。这是在开启优化(如 -O1)时最常用的策略
利用这种实现策略,编译器常常可以优化初始的测试
1 | t = test-expr; |
练习 3.24
1 | long loop_while(long a, long b){ |
练习 3.25
1 | long loop_while2(long a, long b){ |
练习 3.26
1 | long fun_a(unsigned long x){ |
A. 使用中间跳转法
C. 这个函数计算 x 的奇偶校验
for 循环
1 | for (init-expr; test-expr; update-expr) |
翻译为 goto 就是(Guarded-do 形式)
1 | init-expr; |
跳转到中间策略会得到
1 | init-expr; |
练习 3.28
1 | long fun_b(unsigned long x){ |
编译器观察到循环索引 i 被初始化为一个固定的正整数 64。由于 64 显然大于 0,循环条件 i > 0 在第一次进入时必然为真。因此,编译器可以安全地省略初始的测试步骤或跳转到末尾测试的步骤,直接将 for 循环优化为 do-while 形式的控制流。
该函数的作用是反转 64 位无符号整数 x 的二进制位 在 64 次循环中,它每次从 x 的最低位取出一个比特,并将其按顺序推入 val 的右侧。最终结果是,原先 x 的第 0 位变成了 val 的第 63 位,原先 x 的第 1 位变成了 val 的第 62 位,以此类推
练习 3.29
练习题 3.29
A. 如果简单地应用将 for 循环翻译到 while 循环的规则,会得到以下代码:
1 | long sum = 0; |
产生的错误是:在 while 循环中,continue 语句会直接跳转到循环头部的条件测试处(i < 10),从而跳过了循环体末尾的更新表达式 i++。在给出的例子中,一旦 i 的值达到 1,(i & 1) 为真,执行 continue 导致 i 永远无法自增,程序将陷入死循环。
B. 使用 goto 语句来准确模拟 for 循环中 continue 行为的方法是,将跳转目标设在更新表达式之前。代码如下:
1 | long sum = 0; |
这样,无论是否触发跳转,循环变量 i 都会在下一次迭代测试前正常更新,保证了与原 for 循环逻辑的一致性。
过程
过程是软件中一种很重要的抽象。它提供了一种封装代码的方式,用一组指定的参数和一个可选的返回值实现了某种功能
包括::函数(function),方法(method), 子例程(subroutine), 处理函数(handler)等等
要实现过程,机器必须能够处理以下三个基本机制:
- 传递控制:在进入过程时,程序计数器(PC)必须设置为过程代码的起始地址;在返回时,要把 PC 设置为调用指令之后的那条指令的地址。
- 传递数据:调用者必须能够向过程提供参数,过程必须能够向调用者返回一个值。
- 分配和释放内存:在开始时,过程可能需要为局部变量分配空间,并在返回前释放这些空间。
运行时栈
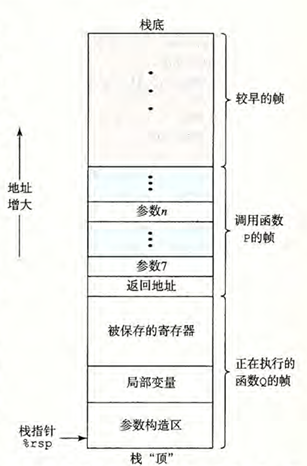
x86-64 的栈向低地址方向增长,而栈指针 %rsp 指向栈顶元素(即最低的地址)
- 入栈 (
pushq S):将栈指针减 8,然后将值写入新的栈顶。 - 出栈 (
popq D):从栈顶读取值,然后将栈指针加 8。
当 x86-64 过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这个空间称为该过程的栈帧(Stack Frame)。栈帧通常用于:
- 存储不能放在寄存器中的局部变量。
- 存储超过 6 个的函数参数(前 6 个通常通过寄存器传递)。
- 保存寄存器的值,以便过程返回后调用者能恢复它们。
转移控制
转移控制涉及将程序计数器从调用者代码跳转到被调用者代码,并在完成后返回。
call Label指令:- 将紧跟在
call指令后面的那条指令的地址(即返回地址)压入栈中。 - 将 PC 设置为
Label的起始地址。
- 将紧跟在
ret指令:- 从栈中弹出地址。
- 将 PC 设置为该地址,从而返回到调用者的执行流中。
这种简单的机制保证了无论过程被调用多少次、从哪里调用,都能正确地返回到调用点。同时,由于返回地址被压入栈中,这也天然地支持了递归调用。
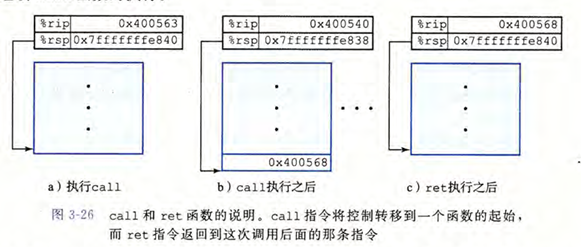
练习 3.32
下面列出的是两个函数 first 和 last 的反汇编代码,以及 main 函数调用 first 的代码
1 | #Disassembly of last(long u, long v) |
每条指令都有一个标号,类似于图 3-27a。从 main 调用 first(10) 开始,到程序返回 main 时为止,填写下表记录指令执行的过程。
| 指令 | 状态值(指令执行前) | |||||||
|---|---|---|---|---|---|---|---|---|
| 标号 | PC | 指令 | %rdi | %rsi | %rax | %rsp | *%rsp | 描述 |
| M1 | 0x400560 | callq | 10 | — | — | 0x7fffffffe820 | — | 调用 first(10) |
| F1 | 0x400548 | lea | 10 | — | — | 0x7fffffffe818 | 0x400565 | 进入first |
| F2 | 0x40054c | sub | 10 | 11 | — | 0x7fffffffe818 | 0x400565 | 计算x-1 |
| F3 | 0x400550 | callq | 9 | 11 | — | 0x7fffffffe818 | 0x400565 | 调用last(9,11) |
| L1 | 0x400540 | mov | 9 | 11 | — | 0x7fffffffe810 | 0x400555 | 进入last |
| L2 | 0x400543 | imul | 9 | 11 | 9 | 0x7fffffffe810 | 0x400555 | 计算 u*v |
| L3 | 0x400547 | retq | 9 | 11 | 99 | 0x7fffffffe810 | 0x400555 | 返回 first |
| F4 | 0x400555 | retq | 9 | 11 | 99 | 0x7fffffffe818 | 0x400565 | 返回 main |
| M2 | 0x400565 | mov | 9 | 11 | 99 | 0x7fffffffe820 | — | 继续执行main |
数据传送
在 x86-64 中,大部分过程的数据传递是通过寄存器实现的,这比以前基于栈的传递方式要快得多。
有六个寄存器可以用来传递最多 6 个整型(包括整数和指针)参数。它们的使用顺序遵循以下惯例:
%rdi:第 1 个参数%rsi:第 2 个参数%rdx:第 3 个参数%rcx:第 4 个参数%r8:第 5 个参数%r9:第 6 个参数
还有6个用来传递回来
%rax:第 1 个返回值
栈上的参数传递
如果一个过程需要的参数多于 6 个,那么超出部分(即第 7 到第 \(n\) 个参数)将通过栈来传递。 - 在调用者调用 call 指令之前,它负责将参数 7 到 \(n\) 按照从后往前的顺序压入自己的栈帧中。 - 参数 7 位于栈顶(距离返回地址最近),参数 8 在更高的地址位置。 - 通过栈传递的数据大小通常都会对齐到 8 字节的倍数。
返回值
过程执行完毕后,通常通过寄存器 %rax 来向调用者返回一个整型结果。
寄存器保护惯例
为了保证过程调用后寄存器的值不被破坏,x86-64 规定了两种保存惯例: - 被调用者保存(Callee-Saved):寄存器 %rbx、%rbp、%r12~%r15。如果过程修改了这些寄存器,必须在返回前将其恢复。 - 调用者保存(Caller-Saved):除被调用者保存寄存器和栈指针 %rsp 之外的所有寄存器。任何过程都可以随意修改它们,调用者如果需要保留这些值,必须在调用前自行保存。
练习 3.33
1 | long procprob(long a, short b, long * u, char * v) |
movslq %edi, %rdi:这表明第 1 个参数的大小是 4 字节(即 int),并被符号扩展为 64 位。addq %rdi, (%rdx):将符号扩展后的第 1 个参数加到第 3 个参数所指向的 8 字节内存中。由于使用了 addq 指令,被指向的类型是 long,因此第 3 个参数的类型是 long *。addb %sil, (%rcx):将第 2 个参数的低 8 位加到第 4 个参数所指向的 1 字节内存中。由于使用了 addb 指令,被指向的类型是 char,因此第 4 个参数的类型是 char *。movl $6, %eax:函数返回值为 6。对应 C 代码中的 sizeof(a) + sizeof(b) = 6。
栈上的局部存储
大多数过程不需要超出寄存器范围的局部存储。但在以下情况下,局部变量必须存放在内存(栈)中:
- 寄存器不足以存放所有的本地数据。
- 对一个局部变量使用了地址运算符
&。 - 局部变量是数组或结构体。
当发生栈上分配时,程序通过减小栈指针 %rsp 来分配空间,并利用 %rsp 加上偏移量的方式来访问这些变量。
寄存器上的局部存储
为了提高效率,编译器优先将局部变量存放在寄存器中。
- 使用被调用者保存寄存器:如果函数决定使用
%rbx等寄存器来存放局部变量,它必须先将这些寄存器的原始值备份在栈中,在函数返回前恢复。 - 使用调用者保存寄存器:如果一个函数不再调用其他子函数(即叶子函数),它可以直接使用任何调用者保存寄存器而无需备份(除了
%rax作为返回值外)。
递归过程
栈和寄存器的组合机制使得递归调用得以实现。
- 每个过程调用在栈中都有它自己的私有状态信息(栈帧)。
- 每次函数调用都会保存其特有的返回地址和本地状态。
- 寄存器保存惯例确保了在递归返回时,上一层调用的寄存器状态(如被调用者保存寄存器的值)能够被正确恢复。
练习 3.35
1 | long rfun(unsigned long x){ |
数组的分配和访问
在 x86-64 中,数组是在内存中连续分配的一块空间。
- 基本原则:对于数据类型
T和整型常数N,声明T A[N]。它在内存中分配一个 \(L \times N\) 字节的连续区域(\(L\) 是T的大小)。 - 指针运算:数组名
A可以看作指向数组开头的指针。A[i]的地址计算公式为:\(x_A + i \times L\)。 - 汇编实现:常利用比例变址寻址模式。例如,若
%rdi存有数组int A[]的起始地址,%rsi存有索引i,指令movl (%rdi,%rsi,4), %eax即可读取A[i]。
异质的数据结构
结构
C 语言的 struct 将可能不同类型的数据对象聚合到一个实体中。
- 内存布局:结构的各字段按照声明顺序在内存中连续排列。
- 访问方式:编译器记录每个字段的偏移量(offset)。访问字段即:基地址 + 偏移量。在汇编中,偏移量是一个硬编码的常数。
联合体
union 允许以多种类型来引用同一个内存块。
- 内存布局:联合的所有成员都从相同的地址(偏移量为 0)开始。
- 大小:联合的总大小等于其最大字段的大小。
- 用途:
- 当已知两个字段互斥时,节省空间。
- 用来访问同一个数据的不同位表示(例如将
double的位解释为long)。
数据对齐
许多计算机系统对基本数据类型的合法地址做出了限制,要求地址必须是某个值 \(K\)(通常是 2, 4 或 8)的倍数
- 对齐原则:x86-64 遵循“K 字节对象的地址必须是 K 的倍数”的规则。例如,
long类型(8 字节)的起始地址必须能被 8 整除。 - 填充 (Padding):为了满足对齐要求,编译器可能在结构体的字段之间或末尾插入间隙。
- 末尾填充:结构体的总大小也必须满足其最宽基本类型的对齐要求,以便在数组中排列时每个元素都保持对齐。
一个大小为 \(K\) 字节的对象,其起始地址 \(A\) 必须满足 \(A \pmod K = 0\)。
| 数据类型 | 大小 (字节) | 对齐要求 (地址必须是…的倍数) |
|---|---|---|
char | 1 | 1 (可以在任何地址开始) |
short | 2 | 2 |
int, float | 4 | 4 |
long, double, pointer | 8 | 8 |
long double | 16 | 16 (在某些 GCC 配置下) |
计算机的内存并不是以字节为单位进行随机访问的,而是以 “块”(Chunk/Word) 为单位。例如,一个 64 位处理器通常一次从内存中读取 8 个字节。
- 对齐访问:如果要读取一个 8 字节的
long,且它存储在 8 的倍数地址上(如 0x08),处理器只需发起一次内存请求,一次性读入这 8 个字节。 - 跨界访问(未对齐):如果该
long存储在 0x04 地址上,它就会跨越两个 8 字节的内存块。处理器可能需要:- 执行两次内存读取操作。
- 通过位移和拼接操作将两部分数据组合在一起。 这会严重降低程序性能。某些架构(如 ARM、MIPS)在遇到未对齐访问时甚至会产生硬件错误。
在 struct 中,编译器必须确保每个字段都满足其对齐要求。这会导致两种形式的 “填充”(Padding)。
A. 内部填充 (Internal Padding)
为了使后续字段对齐,编译器会在两个字段之间插入一些不使用的字节。
示例:
1 | struct S1 { |
B. 末尾填充 (Trailing Padding)
结构体的总大小也必须是其内部最大基本类型字段对齐要求的整数倍。这是为了保证在定义该结构体数组时,数组中的每一个元素都能对齐。
示例:
1 | struct S2 { |
如果不填充,数组 struct S2 arr[2] 的第二个元素 arr[1] 就会从偏移量 5 开始,导致其内部的 int i 无法满足 4 字节对齐。
字段的声明顺序会直接影响结构体所占用的空间大小。一个简单的优化策略是:按照字段大小从大到小排列。
糟糕的布局:
1 | struct S3 { |
优化的布局:
1 | struct S4 { |
指针
指针是 C 语言的核心抽象,在机器级表示为内存地址。
- 类型无关性:在机器代码层面,所有指针都是 8 字节的地址,不区分类型。
- 取地址 (
&):汇编中通常对应leaq指令。 - 间接引用 (
*):汇编中对应内存操作指令,如movq (%rdi), %rax。 - 指针运算:如果
p是T*类型,p + i的实际地址增加量是 \(i \times \text{sizeof}(T)\)。 - 函数指针:其值是该函数可执行代码的第一条指令的地址。可以使用
call *%rax这种间接调用方式。
练习 3.41
A.偏移量如下
1 | p:0 |
B. 一共占用 24 字节
1 | void sp_init(struct prob *sp){ |
练习 3.42
1 | long fun(struxt ELE *ptr){ |
练习 3.43
根据 u_type 的定义,我们首先分析各字段在内存中的偏移量: - t1.u (long) 偏移量为 0,大小 8。 - t1.v (short) 偏移量为 8,大小 2。 - t1.w (char) 偏移量为 10,大小 1。 - t2.a (int[2]) 偏移量为 0,大小 8。 - t2.p (char *) 偏移量为 8,大小 8。
假设 up 在 %rdi 中,dest 在 %rsi 中:
| expr | type | 代码 |
|---|---|---|
up->t1.u | long | movq (%rdi), %raxmovq %rax, (%rsi) |
up->t1.v | short | movw 8(%rdi), %axmovw %ax, (%rsi) |
&up->t1.w | char * | leaq 10(%rdi), %raxmovq %rax, (%rsi) |
up->t2.a | int * | movq %rdi, %raxmovq %rax, (%rsi) |
up->t2.a[up->t1.u] | int | movq (%rdi), %raxmovl (%rdi, %rax, 4), %eaxmovl %eax, (%rsi) |
*up->t2.p | char | movq 8(%rdi), %raxmovb (%rax), %almovb %al, (%rsi) |
解析: 1. up->t1.v:t1 在联合体起始处,v 在其内部偏移量 8 处,大小为 2 字节(short)。 2. &up->t1.w:w 在 t1 内部偏移量 10 处,取其地址使用 leaq。 3. up->t2.a:数组名在表达式中转换为指向其首元素的指针。由于 t2.a 位于联合体起始处,其地址就是 up 的值。 4. up->t2.a[up->t1.u]:首先从偏移量 0 处读取 long 类型的索引 up->t1.u 到 %rax,然后使用比例变址寻址 (%rdi, %rax, 4) 访问 int 数组元素。 5. *up->t2.p:首先从偏移量 8 处读取指针 up->t2.p 到 %rax,然后对该指针进行解引用获取 1 字节的 char
练习 3.44
A. 字段偏移量: i: 0, c: 4, j: 8, d: 12; 总大小: 16 字节; 对齐要求: 4 B. 字段偏移量: i: 0, c: 4, d: 5, j: 8; 总大小: 16 字节; 对齐要求: 8 C. 字段偏移量: w: 0, c: 6; 总大小: 10 字节; 对齐要求: 2 D. 字段偏移量: w: 0, c: 16; 总大小: 40 字节; 对齐要求: 8 E. 字段偏移量: a: 0, t: 24; 总大小: 40 字节; 对齐要求: 8
练习 3.45
A. 该结构中字段的字节偏移量为: a: 0 b: 8 c: 16 d: 24 e: 28 f: 32 g: 40 h: 48
B. 该结构的总大小为 56 字节。
C. 最小化空间浪费的重新排列顺序(按大小降序排列):char *a, double c, long g, float e, int h, short b, char d, char f。 重排后的字节偏移量为: a: 0 c: 8 g: 16 e: 24 h: 28 b: 32 d: 34 f: 35 重排后的总大小为 40 字节(36 字节实际数据加 4 字节末尾填充以满足 8 字节对齐要求)。
内存越界引用和缓冲区溢出
C 语言不进行任何数组边界检查,这使得程序能够向超出分配范围的内存区域写入数据。
- 缓冲区溢出 (Buffer Overflow):当程序试图将比缓冲区更大的数据存入缓冲区时,多出的字节会覆盖相邻的内存。
- 栈溢出机制:在 x86-64 中,局部变量、保存的寄存器值以及函数返回地址都存储在栈上。如果一个局部字符数组发生溢出,它会向上增长并覆盖栈上的返回地址。
- 安全风险:攻击者可以利用这一特性,将返回地址改写为指向一段恶意代码( exploit code)的地址。当函数执行
ret指令时,处理器会跳转并执行这些恶意指令,从而获取系统的控制权。
对抗缓冲区溢出攻击
现代编译器和操作系统采用了多种技术来防御这种攻击:
栈随机化 (ASLR)
- 原理:在程序开始运行时,在栈上分配一段随机大小的占位空间,使得栈的起始地址在每次运行时都不同。
- 目的:使攻击者难以预测注入代码的确切内存地址,从而难以确定改写后的返回地址应该指向哪里。这是一种被称为“地址空间布局随机化”(Address Space Layout Randomization)的更广泛技术的一部分。
栈破坏检测 (栈金丝雀 Stack Canaries)
- 原理:编译器在局部变量和栈状态(如返回地址)之间插入一个特殊的“金丝雀”值(也叫哨兵值)。这个值是在程序运行时生成的随机数。
- 检测过程:在函数返回之前,程序会检查这个金丝雀值是否被修改。
- 结果:如果检测到该值已改变,说明发生了缓冲区溢出,程序会立即终止运行,从而防止执行被篡改的返回地址。
限制可执行代码区域
- 原理:利用硬件(如 NX 位,No-eXecute)将内存区域标记为“只读”、“可读写”或“可执行”。
- 目的:传统的缓冲区溢出攻击通常将代码注入栈中并尝试执行。通过将栈标记为不可执行,即使攻击者成功将恶意指令存入栈缓冲区,处理器也会拒绝执行该内存区域的指令,从而阻断攻击路径。
浮点代码
略
家庭作业
3.58
1 | long decode(long x, long y, long z){ |
3.59
先进行符号扩展 \[ (2^{64} \times x_h + x_l) \times (2^{64} \times y_h + y_l) = 2^{128} \times x_h \times y_h + 2^{64} \times x_l \times y_h + 2^{64} \times x_h \times y_l + x_l \times y_l \] \(2^{128} \times x_h \times y_h\):由于 \(x\) 和 \(y\) 都是 64 位的,因此 \(x_h\) 和 \(y_h\) 只能为 0xFFFFFFFF 或 0x0,代表他们的符号位;并且其乘积不可能超过 128 位,因此这部分可以舍去
\(x_l \times y_l\) 是无符号相乘,其结果可以是 0-128 位,因此他们的结果可以写为 \(2^{64} \times p'_h + p'_l\)
\[ \begin{aligned} 2^{64} \times x_l \times y_h + 2^{64} \times x_h \times y_l + x_l \times y_l &= 2^{64} \times x_l \times y_h + 2^{64} \times x_h \times y_l + 2^{64} \times p'_h + p'_l \\ &= 2^{64} \times ( \underbrace{x_l \times y_h + x_h \times y_l + p'_h}_{\text{高位寄存器 } p_h} ) + \underbrace{p'_l}_{\text{低位寄存器 } p_l} \end{aligned} \]
高位寄存器: \(p_h = x_l \times y_h + x_h \times y_l + p'_h\) 低位寄存器: \(p_l = p'_l\)
| 指令 | 效果 | 描述 |
|---|---|---|
| mulq S | \(S \times R[\%rax] \to R[\%rdx]:R[\%rax]\) | 64位无符号乘法 |
| cqto | 符号扩展(\(R[\%rax]\)) \(\to R[\%rdx]:R[\%rax]\) | 把%rax符号扩展为八字 |
汇编可以画图理解一下
3.60
1 | long loop(long x, int n){ |
rdi 保存 x,esi 保存 n,rax 保存 result,rcx 保存 mask
BCDE 如图
需要注意一个事情
salq %cl, %rdx 中的 %cl 对 long 进行操作,它只看后6位,因此需要对 n 进行模 64 操作,其实可以不必显式的写出,但是这里写出以避免未定义行为
3.61
这里使用了三目运算符,尝试使用条件传送
对于cmovne (%edx),%eax这条机器指令,它被分成了六个顺序执行的部分:取值,译码,执行,访存,写回,更新PC。涉及到的是访存和写回阶段的内容。
cmovne (%edx),%eax在访存阶段会根据%edx的地址值访问内存,得到目标地址的数据val;在接下来的写回阶段,会判断条件码寄存器中的条件是否满足条件传送的条件,如果满足,就将val写入到%eax中。然而问题是,假如%edx的地址是非法的(比如本例中是空地址),即使传送条件不满足也会先进行访存,因为判断条件是否满足这一过程,是在访存后的写回阶段再进行的,故在本例中会导致一个引用空指针错误。
简单理解为一句话,条件传送指令是先取值(访问内存),再看条件是否满足,故可能会引起内存错误
1 | long cread_alt(long *xp){ |
3.62
1 | long result(long *p1, long *p2, mode_t action){ |
3.63
1 | long switch_prob(long x, long n){ |
3.64
对 \(D[i][j]\) 为 \(D+(i*T + j) * 8\)
对 \(A[i][j][k]\) 为 \(A + (i * ST + j*T+k)*8\)
\(8RST=3640\)
\(T=15\)
\(ST=65\)
解得
- \(R = 7\)
- \(S = 5\)
- \(T = 13\)
3.65
rdx
B
rax
C
120/8=15
3.66
NC=4n+1
NR=3*n
3.67
A: 栈帧图在 E 中,存储的值:
- 传出的参数 (0~23):由于结构体 strA 太大,寄存器放不下,所以把 x, y, &z 存在这里,供 process 读取。
- 局部变量 (24~31):变量 z 本来在寄存器
%rdx里,但因为我们需要它的指针,所以存储一份。 - 返回值 (64~87):eval 预先留出了 24 个字节的空位,打算让 process 把计算结果填到这里。
B:
- %rdi (作为隐藏参数): 传递了 &rdi 作为 process 返回量的起始存储地址。
- 栈上的参数: 传递了结构体 s 的全部内容。
C:
当 call process 执行时,会将返回地址压入栈中(占用 8 字节)。因此,在 process 内部,%rsp 比 eval 中的 %rsp 小了 8 字节,eval 中放在 0(%rsp) 的数据,在 process 中变成了 8(%rsp)。 因此访问时,需要将原地址加上 8:
s.a[0]:位于8(%rsp)。汇编第 7 行movq 8(%rsp), %rcx读取了它。s.a[1]:位于16(%rsp)。汇编第 5 行movq 16(%rsp), %rcx读取了它。s.p:位于24(%rsp)。汇编第 2 行movq 24(%rsp), %rdx读取了它。
D:
process 使用 %rdi 寄存器,该寄存器保存了返回结构体 r 的起始地址(由 eval 传入),按照对应的存储空间依次保存即可: * r.u[0]:写入 (%rdi)。对应汇编第 6 行 movq %rcx, (%rdi)。 * r.u[1]:写入 8(%rdi)。对应汇编第 8 行 movq %rcx, 8(%rdi)。 * r.q:写入 16(%rdi)。对应汇编第 9 行 movq %rdx, 16(%rdi)。
E: eval 函数的栈帧图
| 偏移量 (相对于 %rsp) | 存储内容 | 对应变量/描述 |
|---|---|---|
| 104 | (返回地址) | eval 调用者的返回地址 |
| … | … | … |
| 88 | 未使用 | 填充/对齐 |
| 80 | r.q | 结构体 r (返回值) |
| 72 | r.u[1] | 结构体 r (返回值) |
| 64 | r.u[0] | 结构体 r (返回值) |
| … | … | … |
| 32 | 未使用 | 填充/对齐 |
| 24 | z | 局部变量 z (指针 s.p 指向此处) |
| 16 | s.p | 结构体 s (参数,指向 z) |
| 8 | s.a[1] | 结构体 s (参数) |
| 0 | s.a[0] | 结构体 s (参数,栈顶) |
F:
这道题告诉我们关于“大结构体”的两条铁律:
- 传过去:如果参数太大,寄存器装不下,就直接放在栈上传。
- 传回来:如果返回值太大,调用者 (Caller) 负责分配内存空间,并把这块内存的地址传给 被调用者 (Callee),让它往里填。
3.68
int 偏移在 8 处5<=B<=8
long 偏移在 32 处,由于最大是 8
int 结束是 16
short 最小也覆盖到 26
此时 10>=A>=7
184-8 <= A*B*4 <= 184
解得 A=9,B=5
3.69
last 偏移在 0x120 处
a_struct 大小为 40 字节
所以 CNT (288-8)/40=7
idx 所占 8 字节
a_struct大小为40字节,第一个成员idx为long,8字节,还剩32字节 # 第二个成员是long型数组,按照剩余字节,数组大小为4
1 | typedef struct{ |
3.70
A.0 8 0 8
B.16
C.up->e2.x = *(up->e2.next->el.p) - up->e2.next->el.y