逆向工程基本原理01

ARM 架构介绍
RISC:精简指令集计算机(Reduced Instruction Set Computer),是一种计算机架构设计理念,强调使用简单、固定长度的指令集,以提高指令执行效率和简化处理器设计。
例如:ARM、MIPS、RISC-V
CISC:复杂指令集计算机(Complex Instruction Set Computer),是一种计算机架构设计理念,强调使用复杂、可变长度的指令集,以提供更丰富的功能和更高的代码密度。
例如:x86
ARM特性:
- 寄存器数量多
- load/store架构(内存访问有单独的访存指令)
- 定长指令
- 指令条件执行:CSEL X7,X2,X0,EQ if(cond==true) X7 = X2, else X7 = X0
本课程基于 ARMv8架构
ARMv5
ARMv6
- 添加了 VFPv2
- 添加了Jazelle
ARMv7
- 添加了Thumb-2
- 添加了TrustZone
- 添加了SIMD
ARMv8
- 添加了VFPv3/v4
- 添加了NEON Adv SIMD
- A32+T32 ISA
- A64 ISA
- AArch32/64,Scalar FP,SIMD指令
ARM发展历程中里程碑架构
- 增加了可选64位架构:AArch64
- 支持32位和64位指令集:AArch32和AArch64
- 新的64位指令集:A64 ISA(指令长度32位,地址空间64位)
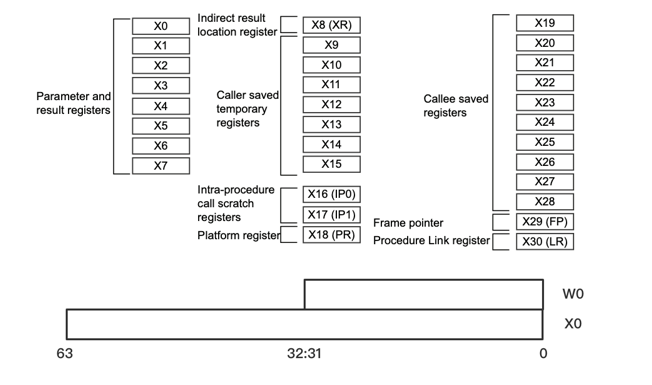
- 拥有31个通用寄存器(X0-X30)和一个栈指针(SP)
- 新的异常处理机制
ARMv8分为AArch32和AArch64两种执行状态
AArch64仅支持A64指令集,AArch32支持A32和T32指令集
只能通过固件设置/特权指令切换不同模式
A32指令集
- 指令宽度: 32bits
- 支持大多数传统的32位ARM指令
- 适用于需要兼容32位ARMv7架构的软件
T32指令集
- 指令宽度: 16/32bits
- 适用于需要更高的代码密度和较小的存储空间的应用
- Thumb 状态下的指令通常占用更少的存储空间,有助于提高系统性能
A64指令级别
- 指令宽度: 32bits
- 64位存储空间
- 和x86-64 不同,使用定长4字节指令加载地址
- 通过两条指令加载内存地址
- adrp:加载变量所在页地址
- add:加载变量页内偏移
- 强大的SIMD和浮点运算支持
31个通用寄存器
每个寄存器为64bits
可以使用Wx来访问Xx的低32bits
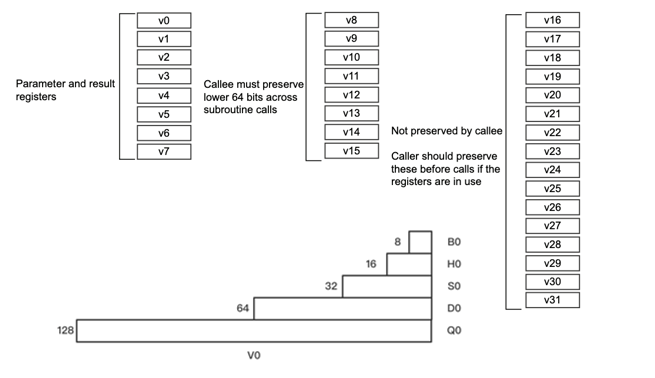
32 个浮点寄存器
每个寄存器为128bits(Qx)
可以访问 8bits(Bx)、16bits(Hx)、32bits(Sx)、64bits(Dx)数据
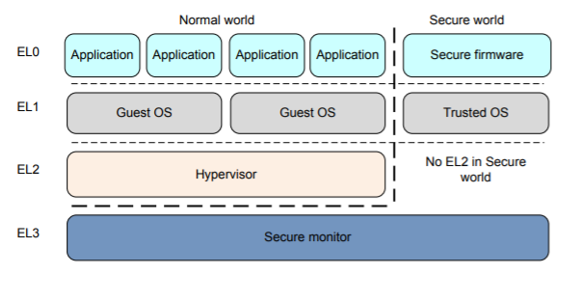
ARMv8 特权级别
- EL0:用户态(User Mode) 用户程序
- EL1:内核态(Kernel Mode)操作系统内核 (OS)
- EL2:Hypervisor Mode(虚拟化模式)虚拟机 (Hypervisor)
- EL3:Secure Monitor Mode(安全监视器模式)低级固件,包括Secure Monitor
特权级别只有在异常发生/结束时发生变化
特权级别切换
当程序运行过程中需要请求更高权限的功能时,需要使用徐通调用来触发异常,从而切换特权级
- SVC:Supervisor Call(超级调用)触发EL0到EL1的切换,常用于用户态程序请求内核服务,例如应用程序调用操作系统内核功能
- HVC:Hypervisor Call(虚拟机调用)触发EL1到EL2的切换,常用于操作系统内核请求虚拟化服务,例如操作系统调用虚拟机功能
- SMC:Secure Monitor Call(安全监视器调用)触发EL2到EL3的切换或者EL1到EL3切换,常用于虚拟机请求安全服务,例如操作系统内核。虚拟机额请求EL3固件功能
特殊寄存器
零寄存器
作为源寄存器时值视为0
程序计数器
- AArch64 中为当前指令地址
- AArch32 中为当前指令地址+8
堆栈寄存器
指向栈顶所在地址
保存程序状态寄存器
存储异常发生前程序状态信息
异常链接寄存器
存储异常发生时的返回地址
程序状态寄存器
- CPSR
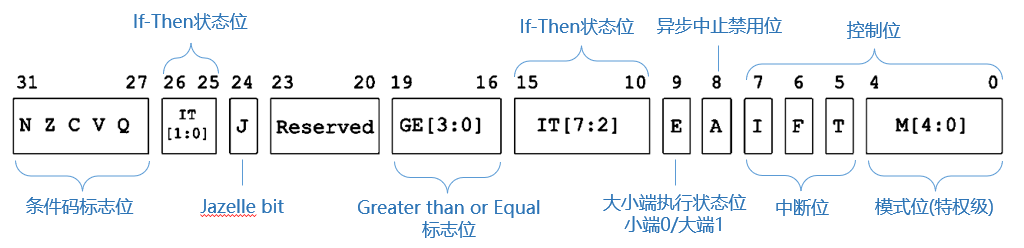
存储了当前执行状态的信息,包括条件码(NZCVQ,与APSR一致)、中断位、特权级等
- APSR
在 EL0 下不能直接访问 CPSR,APSR 是 CPSR 的一个逻辑子集
APSR 只包括 CPSR 中 NZCVQ,GE[3:0] 标志位
异常处理机制
处理器在执行指令过程中遇到异常情况时的处理机制,常见包括:中断、陷阱、终止
CPU 处理器处理异常通常包括以下几个步骤
- 触发异常:软。硬件触发异常
- 保存上下文:保存当前执行的上下文,以便以后恢复执行
- 异常处理:根据不同的异常模式使用不同异常处理
- 恢复执行:根据存储的上下文恢复到异常前的执行现场
ARMv7异常处理
用户模式 (User Mode):处理器执行应用程序代码
快速中断模式 (FIQ,Fast Interrupt Mode):用于处理紧急、低延迟的中断的特殊模式
中断请求模式 (IRQ,Interrupt Request Mode):用于处理标准的中断请求
终止模式 (Abort Mode):用于处理在执行指令或访问内存时发生的异常情况
超级用户模式 (Supervisor Mode):系统内核的运行模式,可以执行特权指令及访问系统资源
监控模式 (Monitor Mode):用于特权级别更低的应用
系统模式 (System Mode):用于处理特殊任务级别,例如处理器上电
指令未定义 (Undefined Mode): 用于处理未定义的指令
当发生异常时,ARMv7会切换到指定模式进行异常处理
ARMv8异常处理
与ARMv7多种异常处理模式不同,ARMv8使用异常级别和异常类型一同决定异常处理模式
- 异常级别(Exception Level,EL):EL0、EL1、EL2、EL3
- 异常类型:Synchronous Exception(同步异常)、IRQ Exception(中断异常)、FIQ Exception(快速中断异常)、SError Exception(系统错误异常)等
ARMv8中每个异常级别都有对应的异常向量表,存储在VBAR_ELn寄存器中
在异常发生时,处理器根据异常级别与异常发生上下文信息(即当前执行状态数据,包括PC、PSR、SP、EL等)选择异常向量表中不同异常处理函数进行异常处理
数据存储的机器级表示
内存和磁盘中,数据以二进制格式存储
逐字节存储,并且采用16进制查看
数据类型
- (u)int8_int(char),(u)int16_t,(u)int64_t
- float,double
- C-string,Unicode-String
- struct,union,class
字长方面,大部分计算机使用 32bits(4 bytes) 作为字长,字长时硬件每次可以处理的数据单元大小
字节序
- 大端存储
- 小端存储
ARM 默认使用小端存储
CTF 题目中有些可能自定义字节序存储方式
C string
使用 ASCII 格式存储
字符串末尾有 ‘’ 终止符
如果字符串长度超过 buffer 大小,可能会移除,覆盖掉保存的 ebp 和 addr
这也是一种攻击手段,攻击者可以通过构造特定的输入来覆盖返回地址,从而执行任意代码
内存访问指令
指令格式
1 | LDR<Sign><size><Destination>, [<address>] |
读写内存的字节数有 <size> 界定,无则由 <Destination> 决定
[<address>] 可以为复杂的表达式
<Sign> 表示这个指令执不执行扩展,比如零扩展或符号扩展
<Destination> 是目标寄存器
- B:1 byte
- H:2 bytes
- W:4 bytes
例如
LDRSB W4, <addr>
Memory :8A
符号扩展把 0x8A 扩展为 0x00000000FFFFFF8A
LDRSB X4, <addr>
Memory :8A
符号扩展把 0x8A 扩展为 0xFFFFFFFFFFFFFF8A
LDRB W4, <addr>
零扩展把 0x8A 扩展为 0x000000000000008A
寻址指令
立即数寻址
1 | MOVZ R0, #254 |
R0 <- 254
寄存器寻址
1 | MOV R0, R1 |
R0 <- R1
寄存器间接寻址
1 | STR R0, [R1] |
[R1] <- R0
寄存器偏移寻址
- 移位命令
1 | LDR R0, R1, LSL, #3 |
R0 <- [R1]左移3位
- 偏移可以为寄存器
1 | LDR R0, [R1, R2] |
R0 <- [R1 + R2]
寄存器基址变址寻址
- 前变址模式
1 | LDR R0, [R1, #4] |
R0 <- [R1 + 4]
- 后变址模式
1 | LDR R0, [R1], #4 |
R0 <- [R1], R1 <- R1 + 4
- 自动变址模式
1 | LDR R0, [R1, #4]! |
R0 <- [R1 + 4], R1 <- R1 + 4
数据处理指令
1 | <op> {cond}{S} <dest>, <lhs>, <rhs> |
条件指令 {cond} 为ARM的特性,根据条件来决定该指令是否执行
如果 {S} 存在,则代表该指令会影响标志位寄存器(CPSR/APSR)
<dest> <lhs> 为寄存器
<rhs> 可以为寄存器或者立即数或者移位偏移
<op> 为 ADD,ADC,AND,BIC,EOR,ORR,RSB,RSC,SBC,SUB,MUL,MLA,DIV,SDIV等
数据对齐
数据对齐的优势
- 数据访问按照对齐的字来访问
- 适配硬件的内存访问方式,提高内存访问效率
- 若数据存储不对齐则需要多次内存访问进行拼接
实现方式:在编译过程中编译器在数据结构中填充空字节(padding)来保证数据对齐
指令对齐
ARMv8 的 AArch32 状态下支持多个指令集
- A32指令集:32位长,4字节对齐
- T32指令集:16/32位长,2字节对齐,旨在优化代码密度和内存效率
- A32 和 T32(Thumb) 指令模式可以切换例如
- 跳转指令BX/BLX 会根据目的地址自动切换A32/T32指令执行模式
- 异常返回时可能会进入A32或T32指令执行模式
- CPSR 的 T 位决定了ARM微处理器执行的是A32指令流还是T32指令流
ARMv8 的 AArch64 状态下仅支持 A64 指令集,指令长度固定为 32 位,4 字节对齐
基础类型的数据对齐
- 1 byte (e.g., char)
no restriction
- 2 bytes (e.g., short)
2字节对齐,lowest 1 bit of address is 0
- 4 bytes (e.g., int, float, etc.)
4字节对齐,lowest 2 bits of address is 00
- 8 bytes (e.g., double)
8字节对齐,lowest 3 bits of address is 000
复杂数据类型的对齐
struct
struct 在内存中占据多个连续字节,依次存储 struct 内部的各个 field
假设下面一个结构体
1 | struct foo{ |
要求如下:
- 结构体内部数据对齐:每个 field 的偏移满足各自对其要求
- 结构体整体对齐
- 结构体整体对齐字长 X 为结构体内 field 对齐字长的最大值
- 结构体的初始地址和结构体大小必须为 X 的整数倍
那么上面结构体对齐如下
1 | struct foo{ |
在 Linux 上查看结构体信息
1 | gcc foo.c -g a.out |
1 | pahole -C foo a.out |
1 | // output |
结构体内数据放置顺序会影响数据对齐,所以结构体内部数据顺序很重要
比较激进的优化会尝试修改结构体内数据顺序来减少 padding 的字节数
union
union 结构中所有 field 共享同一块内存区域,union 的大小为其最大 field 大小
1 | union foo{ |
1 | sizeof(f) = 4 bytes |
union 的大小为最大字段大小
使用联合体打印一个浮点数的二进制
2
3
4
5
6
7
8
9
10
11
float f; // 浮点数
uint32_t u; // 32位无符号整数
};
void printBits(uint32_t num) {
for (int i = 31; i >= 0; i--) {
printf("%d", (num >> i) & 1);
if (i == 31 || i == 23) printf(" ");
}
}
class
类是 C++ 面向对象的基础特性
类
- 用户自定义类型。数据结构
- 成员变量
- 成员函数
对象
- 对象是类的实例化
- 对象占有内存,按照类的类型进行数据存储
- 类中静态变量和静态函数属于 class
构造函数:C++ 类在实例创建中调用的函数,用来初始化类的内部
成员变量
- 默认构造函数
- 含参构造函数
- 拷贝构造函数
- 移动构造函数
析构函数:C++中实例在释放资源前调用的函数,用来清理资源
- 释放实例中使用的资源(memory、file、sockets)
- 注销对其他资源的引用
继承
A 为父类,B 、C 为子类
派生类可以从父类继承一些相同的成员变量和成员函数
可以通过父类来抽象所有的派生类
虚函数
C++方法集成中的重要部分
虚函数是可继承的,且在子类中可以被重写
动态绑定:虚函数呗调用时会根据实例类型动态决定被调用函数
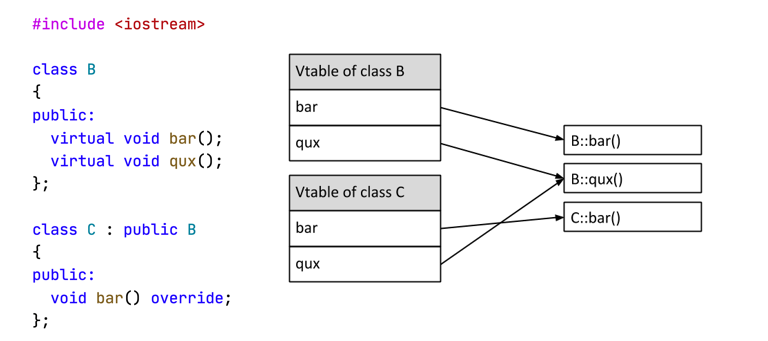
虚函数表
用来实现动态绑定
每个实例都有一个 vtable,可以根据 vtable 来确定被调用的函数
vtable 是相同 class 的实例共享的,可以根据 vtable 确定实例类型
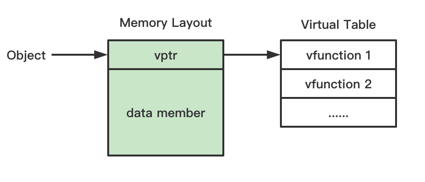
无继承
虚函数表指针在对象内存开头的一个字长的位置
成员变量内存布局和 struct 一样
无继承比较简单,类似 struct,只是在前面多了一个虚函数表,虚函数表也比较简单,顺序排列函数地址即可
考虑下面一个例子
1 | class Animal { |
内存布局如下
1 | 偏移量 内容 大小 说明 |
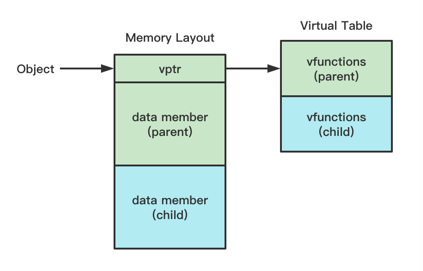
单继承
虚函数表内部按照继承顺序存放虚函数表项
子类中违背重载则用父类版本,如果被重载则用子类版本
子类中新定义的虚函数存放在最后
具体的来说,除了虚函数表以外,其他的布局比较简单:父类和无继承一样,子类先是虚函数表,然后父函数的成员变量,最后是子类自己的成员变量
对于子类的虚函数表,一样的先是父类的虚函数表项,如果子类重载了父类的虚函数,则用子类版本替换父类版本,如果子类没有重载父类的虚函数,则直接使用父类版本。最后,子类中新定义的虚函数被添加到虚函数表的末尾
考虑下面这个例子
1 | class Animal { |
DOG 内存布局如下
1 | 偏移量 内容 大小 说明 |
Dog 的虚函数表如下:
1 | Dog的虚函数表 (vtable for Dog) |
Animal 的虚函数表如下:
1 | Animal的虚函数表 (vtable for Animal) |
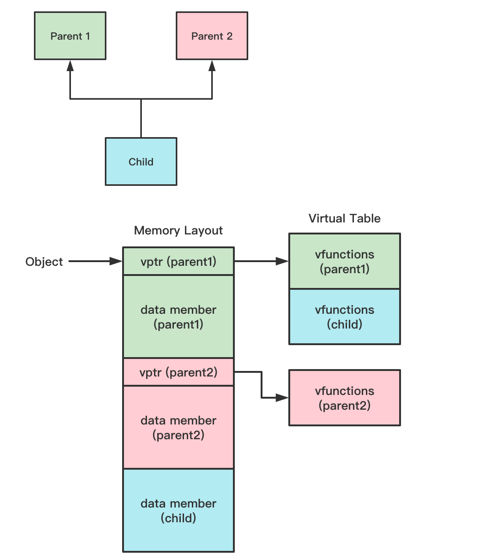
多继承
按照继承顺序排布虚函数表和成员变量
在所有父类数据之后存放子类成员变量
对于每一个虚函数表,子类中未被重载则用父类版本,如果被重载则用子类版本
子类中新定义的虚函数被存放在第一个虚函数表中最后位置
简单来说,子类的内存布局先是第一个父类的虚函数表和成员变量,然后是第二个父类的虚函数表和成员变量,最后是子类自己的成员变量
这个时候,子类有多个虚函数表,第一个父类的虚函数表包含父类的虚函数和子类的虚函数,虚函数表中一样先是父类的基函数,如果被子类重载就用子类版本替换,否则直接使用父类版本,紧接着子类的基函数
第二个父类的虚函数只有父类的虚函数,没有子类的虚函数,如果被子类重载了父类的虚函数,则用子类版本替换父类版本,否则直接使用父类版本
考虑下面这个例子
1 | // 第一个基类:动物 |
PoliceDog 对象的内存布局如下
1 | PoliceDog对象的内存布局(假设在64位系统上): |
下面两个虚函数表
1 | PoliceDog的虚函数表结构: |
C++ RTTI 机制
RTTI(Run-Time Type Information)是 C++ 提供的一种机制,允许程序在运行时获取对象的类型结构信息、继承关系等
基于虚函数表实现
- 编译器会为每个类型创建一个type_info对象
- 虚函数表所在地址之前的一个机器字长会存放type_info对象指针
- typeid运算符:通过对象的虚函数表来获取对应的type_info信息
复杂类型的数据访问
变量基地址+字段偏移
考虑下面的程序
1 | // struct.c |
汇编如下
1 | copy_foo: |
结构体的访问通过基地址加上字段偏移来实现