#计组学习笔记2

CPU 和数据通路
CPU 的功能就是不断取指令并执行指令
一条指令大致会经历:
- 取指令到 IR
- PC 更新
- 指令译码
- 取操作数
- 运算或地址计算
- 访存
- 写回结果
执行过程中还要检测异常和中断
CPU 设计会直接影响性能公式中的 CPI 和时钟周期长度: \[ CPU时间=IC\times CPI\times T \]
其中 IC 主要受 ISA 和编译器影响,而 CPI 和 T 很大程度上由处理器实现方式决定
数据通路和控制器
CPU 可以分成两部分:
- 数据通路:执行部件,负责数据存储、处理和传送
- 控制器:控制部件,负责根据指令产生控制信号
数据通路中有两类元件:
- 操作元件:组合逻辑,如 ALU、加法器、MUX、扩展器
- 状态元件:时序逻辑,如 PC、寄存器、寄存器堆、存储器
组合逻辑的输出只取决于当前输入
状态元件能保存信息,通常在时钟边沿写入新值
数据通路定时
数据通路中只有状态元件能保存信息,组合逻辑元件本身不能保存状态
所以一个同步数据通路通常可以抽象成:
状态元件 → 组合逻辑 → 状态元件
假设采用边沿触发的时序元件,一个时钟周期内大致发生:
- 时钟边沿到来,前一周期的组合逻辑结果写入状态元件
- 经过
Clk-to-Q延迟后,状态元件输出新值 - 新值经过组合逻辑传播,得到本周期结果
- 本周期结果在下个时钟边沿到来前满足建立时间
因此时钟周期至少要满足: \[ T_{clk}\ge T_{clk-to-Q}+T_{comb}+T_{setup}-T_{skew} \]
其中 \(T_{comb}\) 是最长组合逻辑路径延迟,\(T_{setup}\) 是输入状态稳定前的建立时间,\(T_{skew}\) 是时钟偏斜(同一时钟信号到达 不同寄存器时钟引脚的时刻差异)
如图所示,D 触发器采用时钟下降沿触发,要使得输出状态正确随着输入状态改变,需要满足:
- 在时钟下降沿到达前一段时间内,输入端 D 必须稳定有效,这段时间称为建立时间
- 在时钟下降沿到达后一段时间内,输入端 D 必须继续保持稳定不变,这段时间称为保持时间
在满足这个约束条件的情况下,经过时钟下降沿到来后的一段锁存延迟叫做 clk-to-Q ,之后输出端 Q 的状态才会改变,也就是上 \(T_{clk-to-Q}\)
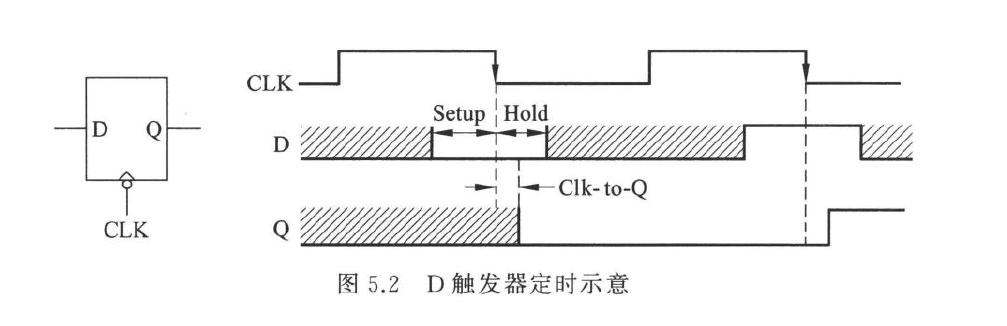
假设在同一个时钟上升沿触发数据传输:
时间 0: 源寄存器时钟边沿到达 → 数据从 D 到 Q 需要 \(T_{clk−to−Q}\)
时间 \(T_{clk−to−Q}\) 数据离开 FF1 的 Q 端,进入组合逻辑 \(T_{comb}\) 延迟
时间 \(T_{clk−to−Q}+T_{comb}\) : 数据到达 FF2 的 D 端
对于 FF2 的时钟边沿
- 如果 FF2 的时钟边沿比 FF1 晚 \(T_{skew}\),则 FF2 的时钟边沿到达时间为 \(T_{clk−to−Q}+T_{comb}+T_{skew}\)
- 如果 FF2 的时钟边沿比 FF1 早 \(T_{skew}\),则 FF2 的时钟边沿到达时间为 \(T_{clk−to−Q}+T_{comb}-T_{skew}\)
为了满足建立时间(Setup Time): 数据必须在 FF2 时钟边沿之前稳定有效,所以: \[ T_{clk-to-Q}+T_{comb} \le T_{clk}+T_{skew}-T_{setup} \]
还要满足保持时间约束: \[ T_{clk-to-Q}+T_{shortest}-T_{skew}>T_{hold} \]
这也是为什么 CPU 设计不仅要画出数据通路,还要分析关键路径
状态元件的读写
寄存器和存储器都有读写操作。
在教材的理想模型中:
- 读操作被看作组合逻辑,地址有效后经过访问时间,输出数据有效
- 写操作被看作时序操作,写使能有效时,在时钟边沿把输入写入指定位置
寄存器堆一般有两个读口和一个写口
两个读口用于同时读出 rs 和 rt,写口用于把结果写回目的寄存器
在单周期处理器中,一条指令从取指、读寄存器、ALU 运算、访存到写回都在一个周期内
RTL
描述指令功能时常用寄存器传送语言 RTL
约定:
- \(R[r]\) 表示寄存器 \(r\) 的内容
- \(M[addr]\) 表示主存地址
addr中的内容 - \(PC\) 表示程序计数器内容
←表示传送方向
比如: \[ R[\$8]\leftarrow M[R[\$9]+4] \]
表示把
$9+4对应内存地址中的内容送到$8
MIPS 指令系统基础
MIPS 是典型的 load-store 结构
普通 ALU 指令只操作寄存器,只有 lw 和 sw 这类访存指令能访问内存
这种结构可以把寄存器看成 CPU 内部的“草稿纸”。数据先从内存 load 到寄存器,计算围绕寄存器进行,最后再 store 回内存。指令条数可能变多,但寄存器访问远快于内存访问,也给编译器做寄存器分配和指令调度留下空间。
三种指令格式
MIPS 指令固定为 32 位,主要有三种格式
R 型:
| 字段 | 位数 | 含义 |
|---|---|---|
| op | 6 | 操作码,R 型通常为 0 |
| rs | 5 | 第一个源寄存器 |
| rt | 5 | 第二个源寄存器 |
| rd | 5 | 目的寄存器 |
| shamt | 5 | 移位量 |
| func | 6 | 功能码 |
I 型:
| 字段 | 位数 | 含义 |
|---|---|---|
| op | 6 | 操作码 |
| rs | 5 | 源寄存器或基址寄存器 |
| rt | 5 | 目的寄存器或源寄存器 |
| imm16 | 16 | 立即数或偏移量 |
J 型:
| 字段 | 位数 | 含义 |
|---|---|---|
| op | 6 | 操作码 |
| target | 26 | 跳转目标字段 |
单周期实验中常实现的指令有:
- R 型:
add、sub、and、or、slt - I 型:
lw、sw、beq、addi - J 型:
j
有些课件中还会把 ori 放进单周期数据通路讨论,它和 addi 类似,只是立即数使用 0 扩展,ALU 做或运算
教材中的单周期数据通路常以 11 条 MIPS 指令作为目标:
| 指令 | 类型 | RTL 含义 |
|---|---|---|
add rd, rs, rt | R | \(R[rd]\leftarrow R[rs]+R[rt]\),判断溢出 |
sub rd, rs, rt | R | \(R[rd]\leftarrow R[rs]-R[rt]\),判断溢出 |
subu rd, rs, rt | R | \(R[rd]\leftarrow R[rs]-R[rt]\),不判断溢出 |
slt rd, rs, rt | R | 带符号小于则置 1 |
sltu rd, rs, rt | R | 无符号小于则置 1 |
ori rt, rs, imm16 | I | \(R[rt]\leftarrow R[rs]\ |\ ZeroExt(imm16)\) |
addiu rt, rs, imm16 | I | \(R[rt]\leftarrow R[rs]+SignExt(imm16)\),不判断溢出 |
lw rt, rs, imm16 | I | \(R[rt]\leftarrow M[R[rs]+SignExt(imm16)]\) |
sw rt, rs, imm16 | I | \(M[R[rs]+SignExt(imm16)]\leftarrow R[rt]\) |
beq rs, rt, imm16 | I | 相等则转移 |
j target | J | 无条件跳转 |
其中 addiu 的名字里有 u,但立即数仍然要符号扩展;这里的 u 主要表示不进行溢出异常处理
固定长度指令的一个好处是译码简单。MIPS 的 op 字段位置固定,硬件可以直接截取固定比特并查表译码;可变长指令则需要先判断指令边界和操作码长度,前端译码复杂得多。
寻址方式
MIPS 中常见寻址方式:
- 寄存器寻址:操作数在寄存器中,如
add rd, rs, rt - 立即数寻址:操作数来自指令中的立即数字段,如
addi rt, rs, imm - 基址寻址:有效地址为 \(R[rs]+SignExt(imm16)\),如
lw和sw - PC 相对寻址:分支目标为 \(PC+4+SignExt(imm16)\times 4\)
- 伪直接寻址:跳转目标由
PC+4高位和target字段拼接得到
MIPS 按字节编址,一条指令 4 字节,所以顺序执行时: \[ PC \leftarrow PC+4 \]
同样一段二进制字段,在不同寻址方式下含义可能完全不同。它可以表示立即数,也可以表示寄存器编号,还可以参与有效地址计算。因此寻址方式的核心作用,是规定操作数从哪里来,以及有效地址如何形成。
单周期处理器
单周期处理器的特点是:
一条完整指令在一个时钟周期内完成
因此: \[ CPI=1 \]
看起来很好,但问题是时钟周期必须能容纳最慢指令的完整执行过程。
通常最慢的是 lw
设计步骤
处理器设计大致按下面步骤:
- 分析每条指令功能,用 RTL 表示
- 找出实现这些功能需要哪些部件
- 连接各部件形成数据通路
- 确定每条指令的控制信号
- 汇总控制信号,设计控制器
单周期处理器中,所有控制信号在一条指令执行期间保持稳定
单周期的本质
单周期处理器是把一条指令所需的所有微操作都压进一个长时钟周期里完成
比如 lw 在一个周期内要完成:
- 用 PC 访问指令存储器
- 读寄存器堆
- 扩展立即数
- ALU 计算数据地址
- 访问数据存储器
- 选择写回数据
- 写寄存器堆
- 计算下条 PC
所以单周期控制器相对简单,但时钟周期被最长路径拖长
取指令部件
所有指令都有公共操作:
\[ Instruction \leftarrow M[PC] \]
\[ PC \leftarrow PC+4 \]
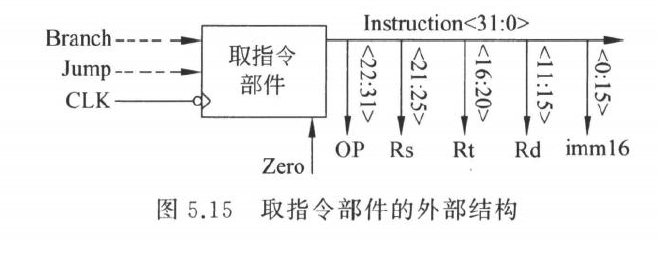
因此需要:
- PC 寄存器
- 指令存储器
- PC+4 加法器
- 下一地址选择逻辑
正常顺序执行时,下一条指令地址是 PC+4
分支指令成立时: \[ PC \leftarrow PC+4+SignExt(imm16)\times 4 \]
跳转指令时: \[ PC \leftarrow (PC+4)[31:28]\ ||\ target[25:0]\ ||\ 00 \]
这里最后补两个 0,是因为 MIPS 指令按 4 字节对齐,指令地址最低两位必为 0
下址逻辑
取指令部件真正要做的是选择下一个 PC
常见候选值有三类:
- 顺序地址:\(PC+4\)
- 分支地址:\(PC+4+SignExt(imm16)\times 4\)
- 跳转地址:\((PC+4)[31:28]\ ||\ target[25:0]\ ||\ 00\)
因此取指部件至少需要:
- 一个 PC 寄存器
- 一个指令存储器
- 一个计算
PC+4的加法器 - 一个计算分支目标的加法器
- 一个根据
Branch、Zero和Jump选择下址的 MUX
注意:取指和 PC 更新在同一个周期中并行发生,PC 的新值要到下个时钟边沿才写入,所以不会影响当前指令的读取
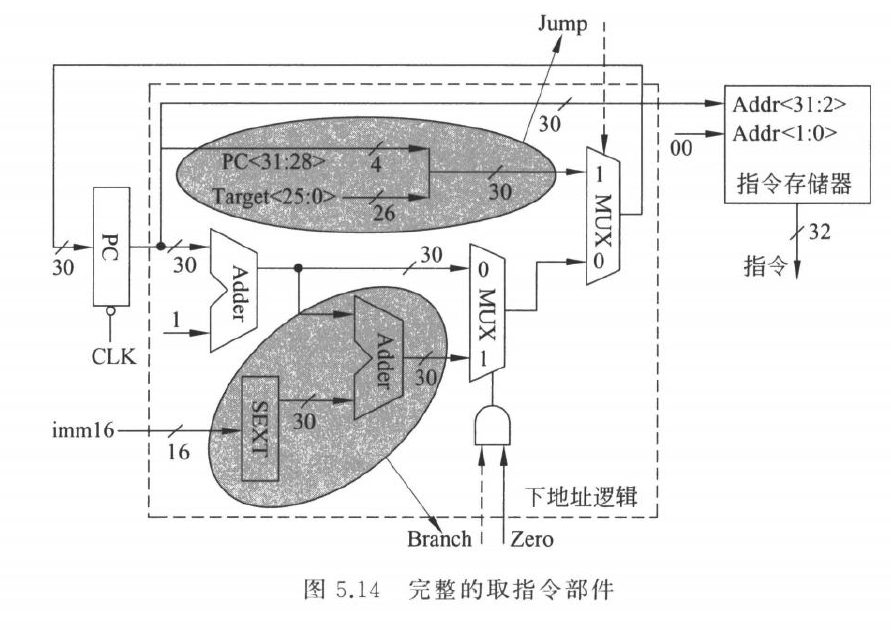
各类指令的数据通路
单周期数据通路的设计方法是逐类指令分析,然后把所有需要的路径合并
合并时的原则是:
- 能共用的功能部件尽量共用
- 多个可能来源接到同一输入时,用 MUX 选择
- 每个 MUX 都要有对应控制信号
- 所有会写状态的部件都要有写使能或写控制
- 不同指令不使用的路径可以保持任意值,但不能错误写状态
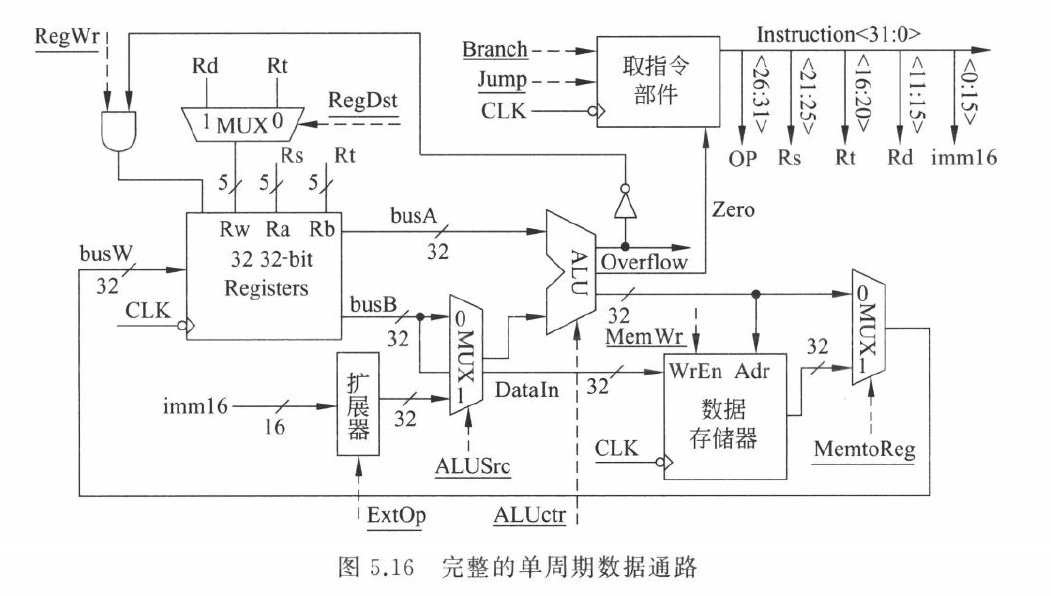
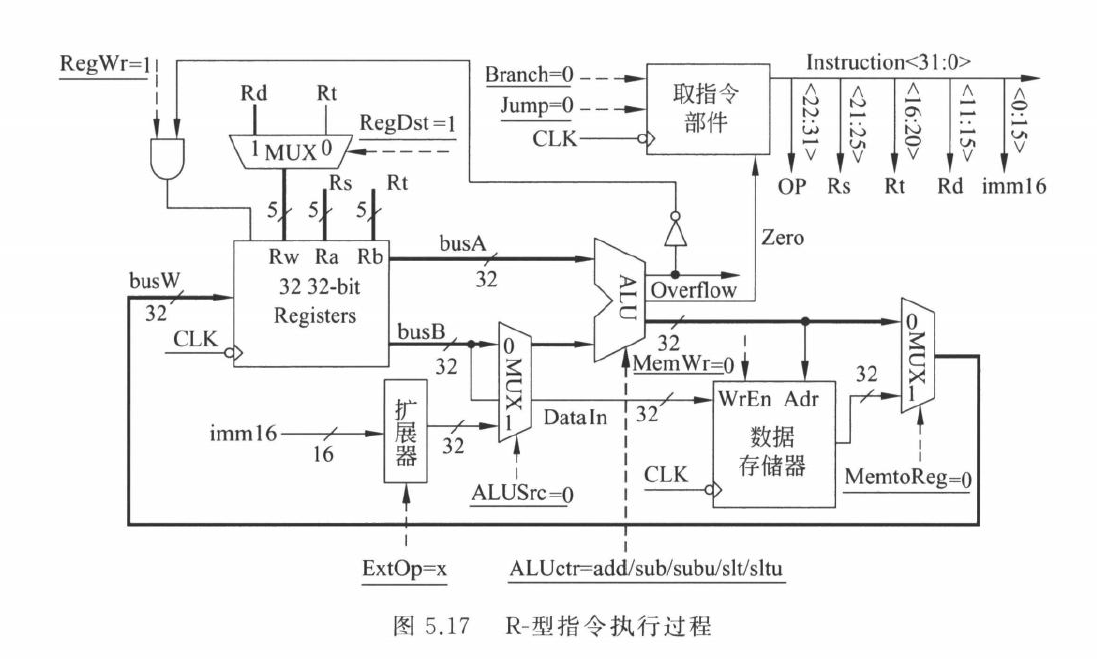
R 型指令
以 add rd, rs, rt 为例:
\[ R[rd]\leftarrow R[rs]+R[rt] \]
需要:
- 从寄存器堆读
rs和rt - ALU 对两个寄存器值做运算
- 结果写回
rd
主要控制信号:
RegDst=1,目的寄存器选rdALUSrc=0,ALU 第二操作数来自寄存器MemtoReg=0,写回数据来自 ALURegWrite=1,写寄存器MemWrite=0,不写内存Branch=0Jump=0
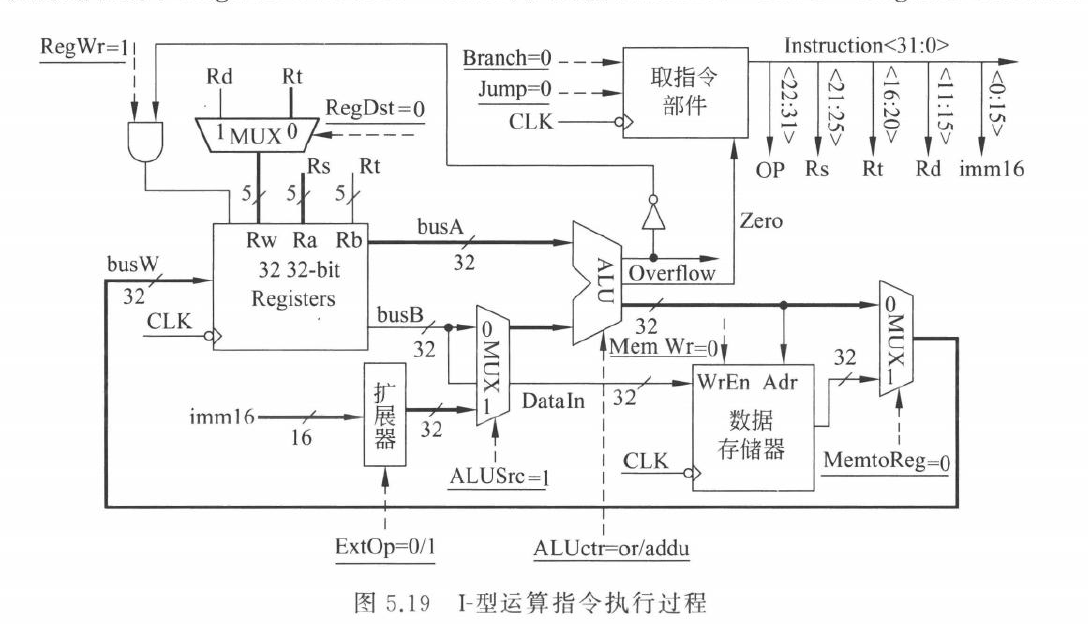
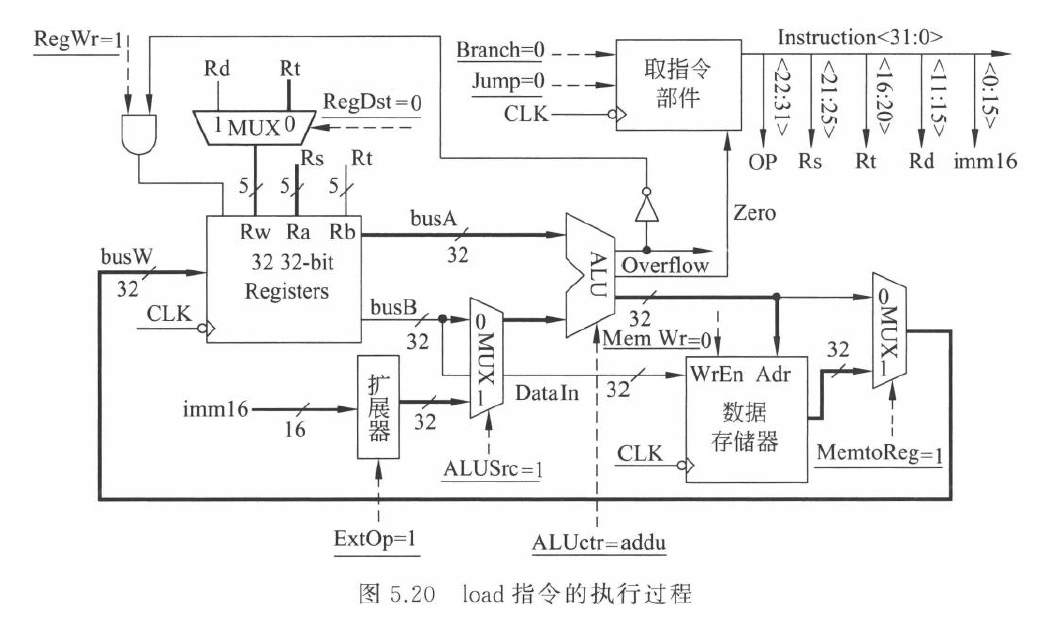
lw 指令
lw rt, imm(rs) 的 RTL: \[ Addr \leftarrow R[rs]+SignExt(imm16) \]
\[ R[rt]\leftarrow M[Addr] \]
需要:
- 读基址寄存器
rs - 立即数符号扩展
- ALU 计算数据地址
- 数据存储器读
- 读出的数据写回
rt
主要控制信号:
RegDst=0,目的寄存器选rtALUSrc=1,ALU 第二操作数来自扩展立即数MemtoReg=1,写回数据来自数据存储器RegWrite=1MemWrite=0ExtOp=1,符号扩展
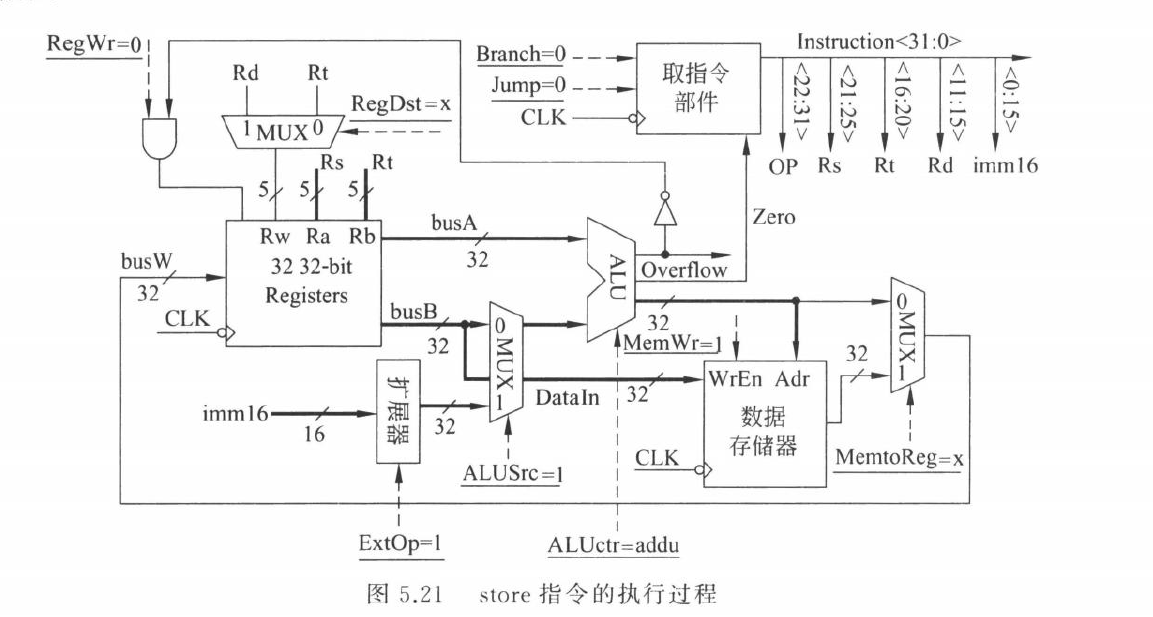
sw 指令
sw rt, imm(rs) 的 RTL:
\[ Addr \leftarrow R[rs]+SignExt(imm16) \]
\[ M[Addr]\leftarrow R[rt] \]
sw 不写寄存器,只写内存。
主要控制信号:
ALUSrc=1MemWrite=1RegWrite=0ExtOp=1
addi 和 ori
addi rt, rs, imm: \[ R[rt]\leftarrow R[rs]+SignExt(imm16) \]
ori rt, rs, imm: \[ R[rt]\leftarrow R[rs]\ or\ ZeroExt(imm16) \]
两者都把结果写到 rt。
差别是:
addi使用符号扩展,ALU 做加法ori使用 0 扩展,ALU 做或运算
beq 指令
beq rs, rt, label:
\[ if\ R[rs]=R[rt]\ then\ PC \leftarrow PC+4+SignExt(imm16)\times 4 \]
ALU 用减法判断两个寄存器是否相等
如果: \[ R[rs]-R[rt]=0 \]
则 Zero=1,分支成立
因此: \[ PCSrc=Branch \land Zero \]
j 指令
j target 不访问寄存器,也不访问数据存储器
只修改 PC: \[ PC \leftarrow (PC+4)[31:28]\ ||\ target[25:0]\ ||\ 00 \]
控制信号中只需要 Jump=1,并保证寄存器堆和数据存储器不发生写操作
普通 j target 只修改 PC,不保存返回地址。函数调用通常使用 jal target,它会把返回地址保存到 $31 也就是 $ra,然后跳到目标函数。函数返回时再执行 jr $ra,把 $ra 的值送回 PC。
控制信号
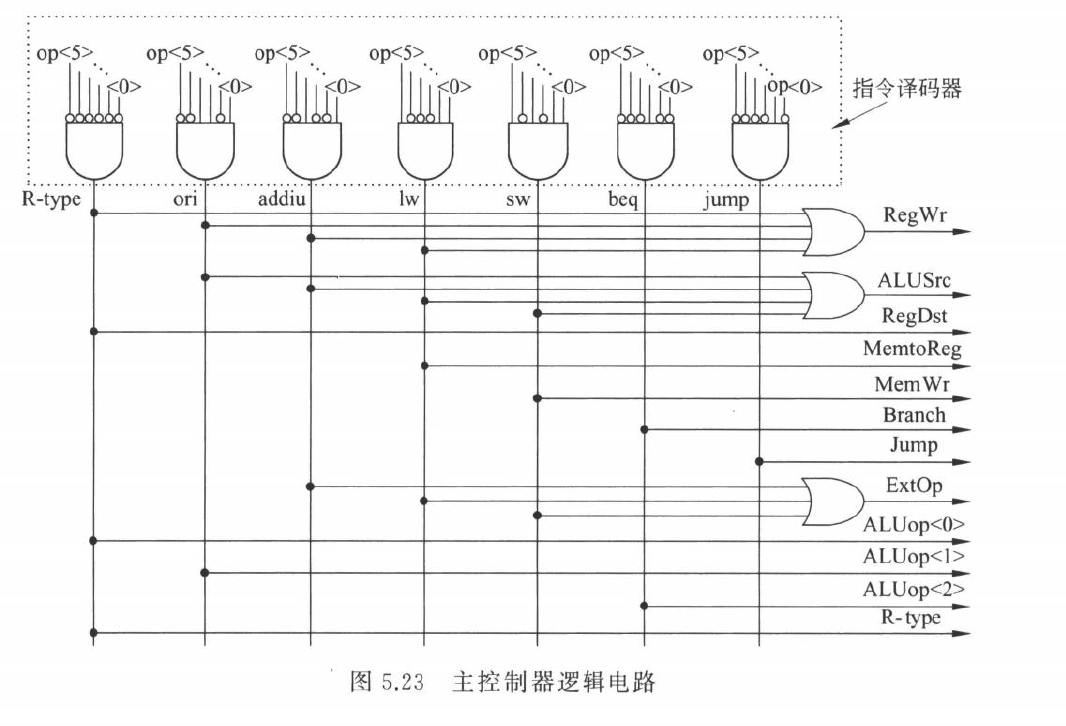
单周期主控制器根据 op 字段产生控制信号
常见控制信号如下:
| 信号 | 含义 |
|---|---|
| RegDst | 选择目的寄存器是 rt 还是 rd |
| ALUSrc | 选择 ALU 第二操作数来自寄存器还是立即数 |
| MemtoReg | 选择写回数据来自 ALU 还是内存 |
| RegWrite | 是否写寄存器堆 |
| MemWrite | 是否写数据存储器 |
| Branch | 是否为分支指令 |
| Jump | 是否为跳转指令 |
| ExtOp | 立即数符号扩展还是 0 扩展 |
| ALUOp | 指示 ALU 操作类型 |
控制表:
| 指令 | RegDst | ALUSrc | MemtoReg | RegWrite | MemWrite | Branch | Jump | 说明 |
|---|---|---|---|---|---|---|---|---|
| R-type | 1 | 0 | 0 | 1 | 0 | 0 | 0 | ALU 运算,写 rd |
| lw | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 读内存,写 rt |
| sw | x | 1 | x | 0 | 1 | 0 | 0 | 写内存 |
| beq | x | 0 | x | 0 | 0 | 1 | 0 | ALU 做减法比较 |
| addi | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 加立即数 |
| ori | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 或立即数 |
| j | x | x | x | 0 | 0 | 0 | 1 | 改 PC |
这里的 x 表示不关心
如果实现教材中的 11 条指令,控制表会比上面更细致一些,因为 slt 和 sltu 需要区分带符号和无符号比较,sub 和 subu 需要区分是否判断溢出
主要差异是:
- R 型中不同
func会产生不同 ALU 操作 ori使用 0 扩展,addiu/lw/sw/beq使用符号扩展add/sub/slt等可能涉及带符号判断或溢出判断subu/sltu/addiu/lw/sw/beq一般不产生溢出异常
因此主控制器不应该直接把所有 ALU 内部信号都列出来,而是先输出 ALUOp,再由 ALU 局部控制器结合 func 生成具体 ALUctr
数据通路中的许多信号会同时被组合逻辑计算出来。某条指令没有选择某一路,并不意味着那一路没有值,而是这个值不会进入最终写回或状态更新路径。分析数据通路时要区分“值存在”和“值被使用”。
ALU 控制器
主控制器不一定直接给出 ALU 的所有细节控制
常见做法是:
- 主控制器根据
op产生ALUOp - ALU 局部控制器再结合
func字段产生ALUControl
例如:
| ALUOp | funct | ALUControl | 用途 |
|---|---|---|---|
| 00 | x | add | lw、sw、addi |
| 01 | x | sub | beq |
| 10 | 100000 | add | add |
| 10 | 100010 | sub | sub |
| 10 | 100100 | and | and |
| 10 | 100101 | or | or |
| 10 | 101010 | slt | slt |
这样主控制器只需要识别指令大类,具体 R 型运算交给 func 字段处理
主控制器根据 op 只能判断一条指令是不是 R 型,不能仅靠 op 确定它到底是 add、sub 还是 slt。R 型指令还要继续根据 func 字段生成具体的 ALUctr,这就是主控制器和 ALU 局部控制器分层的原因。
ALUctr 编码
教材中把 ALU 操作编码成 3 位 ALUctr:
| ALUctr | 操作 |
|---|---|
001 | add |
101 | sub |
100 | subu |
010 | or |
111 | slt |
110 | sltu |
ALU 内部再根据 ALUctr 产生更底层的控制信号
例如:
SUBctr:是否做减法OVctr:是否判断溢出SIGctr:比较时是否按带符号数处理OPctr:选择加减、或、小于置位等输出
这样分层后,主控制器只处理指令级信息,ALU 控制器处理运算器内部信息
主控制器实现
主控制器的输入主要是 op 字段
每个控制信号都可以由各条指令译码结果相或得到
例如: \[ RegWrite=Rtype\lor ori\lor addiu\lor lw \]
这些指令都会写寄存器
同理: \[ MemWrite=sw \]
\[ Branch=beq \]
\[ Jump=j \]
硬件上可以先用指令译码器把 op 译成若干指令类型信号,再用组合逻辑生成控制信号
这种硬连线控制器速度快,适合 MIPS 这种规整指令集
单周期时序
单周期处理器中,一条指令必须在一个时钟周期内完成。
以 lw 为例,关键路径大致为:
- PC 输出有效
- 指令存储器读出指令
- 寄存器堆读出
rs - 立即数扩展
- ALU 计算地址
- 数据存储器读数据
- 数据送到寄存器堆写入口
- 下个时钟边沿写入寄存器
因此 lw 的关键路径为: \[ T_{clk}=T_{PC\ clk-to-Q}+T_{IMem}+T_{RegRead}+T_{ALU}+T_{DMem}+T_{setup}+T_{skew} \]
所有指令都必须使用这个时钟周期,即使 j 指令只需要很短的路径。
这就是单周期处理器性能不高的根本原因。
关键路径 lw
lw 同时经过指令存储器和数据存储器,还要读寄存器、做 ALU 地址计算、写寄存器
R 型指令不访问数据存储器
sw 不写寄存器。
beq 不访问数据存储器,也不写寄存器。
j 基本只需要取指和改 PC
所以 lw 的组合路径最长,单周期时钟周期通常由它决定
这会导致一个明显浪费:简单指令也要等待和 lw 一样长的周期
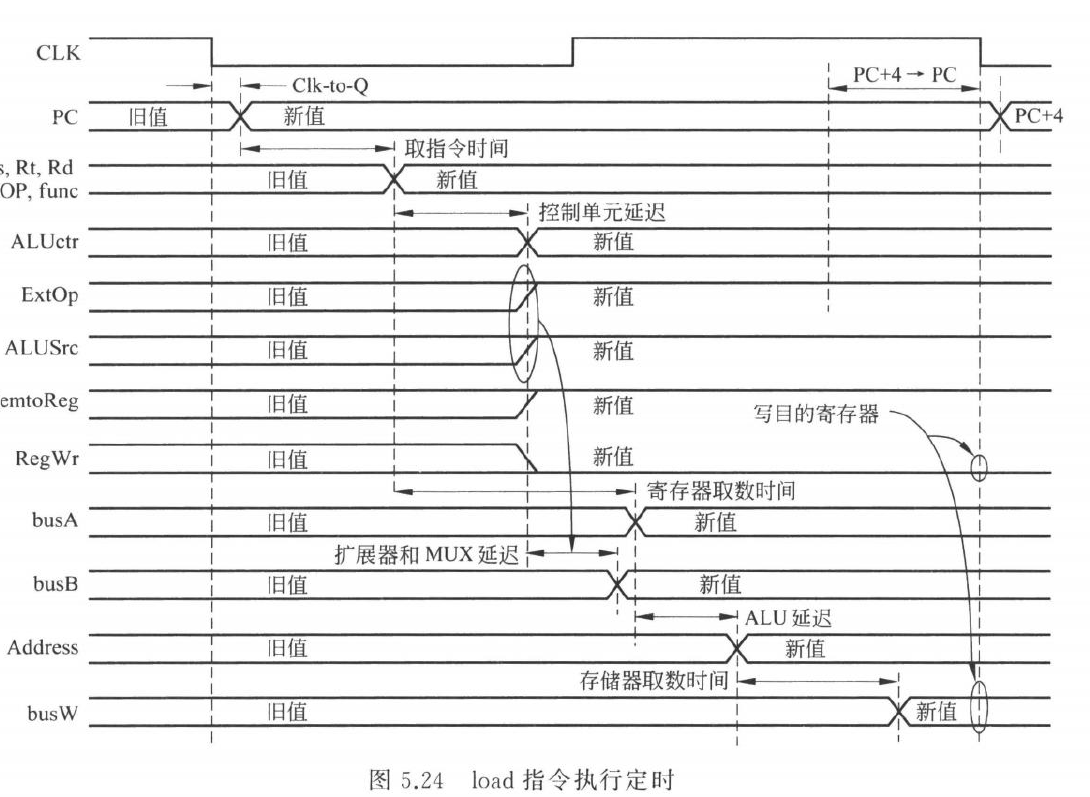
状态更新的位置
单周期中,所有状态更新都发生在周期末尾的时钟边沿
可能被写的状态包括:
- PC
- 寄存器堆
- 数据存储器
在时钟边沿到来前,写入这些状态元件的数据和控制信号必须已经稳定
比如 lw 的数据要先通过 MemtoReg MUX 到达寄存器堆写端口,RegWrite 也要稳定为 1,才能在时钟边沿写入 rt
性能例子
假设:
- 存储器访问时间:200ps
- ALU 和加法器:100ps
- 寄存器堆读写:50ps
- MUX、控制器、扩展器延迟忽略
各类指令大致时间:
lw:600pssw:550ps- ALU 指令:400ps
- 分支:350ps
- 跳转:200ps
单周期实现必须取最长的 600ps 作为时钟周期。
如果假想每类指令都能用不同周期,按指令比例:
- 25% 取数
- 10% 存数
- 45% ALU
- 15% 分支
- 5% 跳转
平均周期为: \[ 600\times25\%+550\times10\%+400\times45\%+350\times15\%+200\times5\%=447.5ps \]
性能比约为: \[ \frac{600}{447.5}\approx 1.34 \]
但可变时钟周期实现复杂,收益也有限,所以现代处理器不会采用这种简单单周期方式
单周期中的异常问题
如果指令执行过程中发生异常,比如 add 溢出,处理器不能把错误结果写回寄存器
因此带异常处理的数据通路需要额外考虑:
- 如何检测异常
- 如何禁止当前指令写回错误结果
- 如何保存断点
- 如何记录异常原因
- 如何把 PC 改为异常处理程序入口
常用特殊寄存器:
EPC:保存异常断点Cause:保存异常原因
MIPS 常见异常入口为: \[ 0x80000180 \]
如果异常属于故障类,需要重新执行发生异常的指令,那么 EPC 应保存该指令地址
在单周期或多周期图中,取指后 PC 往往已经变成 PC+4,所以保存断点时经常需要使用 PC-4
这部分在多周期和流水线里更重要,因为异常响应要和指令执行阶段、PC 当前值严格对应
带溢出检查的 add/sub 可以先把结果算到临时路径上,再根据 Overflow 判断是否允许写回。如果发生溢出,RegWrite 应被禁止,错误结果不能进入目的寄存器。随后 PC 转向异常处理入口,由异常处理程序决定后续行为。