主定理和分治

本分类完全基于课程内容和算法导论的内容,如果有和数据结构(H)重合的内容会跳过,可以参考对应的数据结构(H)的相关内容
循环不变式
循环不变式有点类似于数学归纳法
循环不变式要求证明以下三条性质
- 初始化:循环的第一次迭代之前,循环不变式为真
- 保持:如果循环不变式在某次迭代之前为真,那么在该迭代之后它仍然为真
- 终止:当循环结束时,循环不变式为真,并且循环的结束条件为真,这些条件共同保证了算法的正确性
伪代码
下面与算法导论中伪代码规定的风格保持一致
约定:
- 缩进表示块结构例如,第1行开始的
for循环体由第2 到 8行组成,第5行开始的while循环体包含第 6~7 行但不包含第8行。我们的缩进风格也适用于if-else语句。采用缩进来代替常规的块结构标志,如begin和end语句,可以大大提高代码的清晰性。 - while、
for与repeat-until等循环结构以及if-else等条件结构与C、C++、Java、Python和Pascal中的那些结构具有类似的解释。不像某些出现于C++、Java和Pascal中的情况,本书中在退出循环后,循环计数器保持其值。因此,紧接在一个for循环后,循环计数器的值就是第一个超出for循环界限的那个值。在证明插入排序的正确性时,我们使用了该性质。第1行的for循环头为for j = 2 to A.length,所以,当该循环终止时,j=A.length+1(或者等价地,j=n+1,因为n=A.length)。当一个for循环每次迭代增加其循环计数器时,我们使用关键词to。当一个for循环每次选代减少其循环计数器时,我们使用关键词downto。当循环计数器以大于1的一个量改变时,该改变量跟在可选关键词by之后。 - 符号“//”表示该行后面部分是个注释
- 形如
i=j=e的多重赋值将表达式e的值赋给变量i和j;它应被处理成等价于赋值j=e后跟着赋值i=j - 变量(如
i、j和key)是局部于给定过程的。若无显式说明,我们不使用全局变量 - 数组元素通过“数组名[下标]”这样的形式来访问。例如,
A[i]表示数组A的第i个元素。记号“.”用于表示数组中值的一个范围,这样,A[1..j]表示A的一个子数组,它包含j个元素A[1],A[2],...,A[j] - 复合数据通常被组织成对象,对象又由属性组成。我们使用许多面向对象编程语言中创建的句法来访问特定的属性:对象名后跟一个点再跟属性名。例如,数组可以看成是一个对象,它具有属性
length,表示数组包含多少元素,如A.length就表示数组A中的元素数目 - 我们按值把参数传递给过程:被调用过程接收其参数自身的副本。如果它对某个参数赋值,调用过程看不到这种改变。当对象被传递时,指向表示对象数据的指针被复制,而对象的属性却未被复制。例如,如果x是某个被调用过程的参数,在被调用过程中的赋值
x=y对调用过程是不可见的。然而,赋值x.f=3却是可见的。类似地,数组通过指针来传递,结果指向数组的一个指针被传递,而不是整个数组,单个数组元素的改变对调用过程是可见的 - 一个
return语句立即将控制返回到调用过程的调用点。大多数return语句也将一个值传递回调用者。我们的伪代码与许多编程语言不同,因为我们允许在单一的return语句中返回多个值 - 布尔运算符“and”和“or”都是短路的。也就是说,当求值表达式“x and y”时,首先求值x。如果x求值为 FALSE,那么整个表达式不可能求值为TRUE,所以不再求值y。另外,如果 x 求值为 TRUE,那么就必须求值y以确定整个表达式的值。类似地,对表达式“x or y”,仅当x求值为FALSE时,才求值表达式y。短路的运算符使我们能书写像“ x≠NIL and x.f=y” 这样的布尔表达式,而不必担心当 x 为 NI L时我们试图求值 x.f 将会发生什么情况
- 关键词
error表示因为已被调用的过程情况不对而出现了一个错误。调用过程负责处理该错误,所以我们不用说明将采取什么行动
时间复杂度
以插入排序为例,分析其时间复杂度
1 | INSETION-SORT(A) |
每行代价如下:
| 行号 | 代价 | 执行次数 |
|---|---|---|
| 2 | \(c_1\) | \(n\) |
| 3 | \(c_2\) | \(n-1\) |
| 4 | 0 | \(n-1\) |
| 5 | \(c_4\) | \(n-1\) |
| 6 | \(c_5\) | \(\Sigma_{j=2}^{n}t_j\) |
| 7 | \(c_6\) | \(\Sigma_{j=2}^{n}(t_j-1)\) |
| 8 | \(c_7\) | \(\Sigma_{j=2}^{n}(t_j-1)\) |
| 9 | \(c_8\) | \(n-1\) |
那么该算法的最终运行时间就是执行每条语句的运行时间之和: \[ T(n) = c_1n + c_2(n-1) + c_4(n-1) + c_5\Sigma_{j=2}^{n}t_j + c_6\Sigma_{j=2}^{n}(t_j-1) + c_7\Sigma_{j=2}^{n}(t_j-1) + c_8(n-1) \] 但该算法也有可能因为输入数据的不同而有不同的运行时间,例如当输入数据已经是有序的时,算法的运行时间就会更短一些,对于最佳情况 \[ T(n) = c_1n + c_2(n-1) + c_4(n-1) + c_5\Sigma_{j=2}^{n}1 + c_6\Sigma_{j=2}^{n}(1-1) + c_7\Sigma_{j=2}^{n}(1-1) + c_8(n-1) \\ = (c_1+c_2+c_4+c_5+c_8)n - (c_2+c_4+c_5+c_8) \] 可以把运行时间表示为 \(an+b\) ,其中 \(a\) 和 \(b\) 是常数,它是关于 \(n\) 的线性函数
但也存在最坏情况,例如当输入数据是逆序时,算法的运行时间就会更长一些,此时 \[ T(n) = c_1n + c_2(n-1) + c_4(n-1) + c_5\Sigma_{j=2}^{n}j + c_6\Sigma_{j=2}^{n}(j-1) + c_7\Sigma_{j=2}^{n}(j-1) + c_8(n-1) \\ = \frac{1}{2}(c_5+c_6+c_7)n^2 + (c_1+c_2+c_4+c_8)n - \frac{1}{2}(c_5+c_6+c_7)n - (c_2+c_4+c_5+c_8) \] 这个时候最坏运行时间是关于 \(n^2\) 的二次函数
最坏情况与平均情况分析
一般情况下,我们更关心算法的最坏情况运行时间,因为它能保证算法在任何输入下都不会超过这个时间,不必对这个算法猜测是否存在更坏的情况,而某些算法会经常性出现最坏情况
但有些时候,我们也会关心算法的平均情况运行时间,有时随机化算法做出的随机选择使得应该进行概率分析得出期望时间
增长量级
算法的增长量级是指当输入规模趋近于无穷大时,算法的运行时间的增长趋势。,例如 \(\Theta(n)\) 表示线性增长,\(\Theta(n^2)\) 表示二次增长,\(\Theta(\log n)\) 表示对数增长等。算法的增长量级可以帮助我们比较不同算法在处理大规模输入时的效率,并选择最适合的算法来解决问题
分治思想
分治法的一般框架:
- 分解:把规模为 \(n\) 的问题分成若干个规模更小的子问题
- 解决:递归地求解这些子问题
- 合并:把子问题的解合并成原问题的解
以归并排序为例:
1 | MERGE-SORT(A, p, r) |
其中 MERGE 的输入是两个已经排好序的子数组 \(A[p..q]\) 和 \(A[q+1..r]\),每次比较两个子数组当前还没有被取走的最小元素,把较小者放入结果数组。这个过程的循环不变式可以写成:
在每次循环开始时,结果数组中已经放入的是两个子数组已处理部分的最小若干个元素,并且它们已经有序。
因此每次选择两个当前首元素中的较小者都是安全的;当某个子数组为空时,把另一个子数组剩余部分直接接到后面即可。由于每个元素只被取出一次,合并过程的时间为 \(\Theta(n)\)。
归并排序的最坏时间满足 \[ T(n)=2T(n/2)+\Theta(n) \] 用递归树看,每一层的合并总代价都是 \(\Theta(n)\),递归深度为 \(\log n\),叶子节点总贡献为 \(\Theta(n)\),所以 \[ T(n)=\Theta(n\log n) \]
注意归并排序的递归划分不依赖输入是否已经有序,所以即使输入本来排好序,它仍然会递归拆分并合并,最坏情况下仍是 \(\Theta(n\log n)\)。这和插入排序在有序输入上为线性时间不同。
更多分治递归的写法参考递归和非递归 | exdoubled’s blog
函数的增长
\(\Theta\) 符号
对于一个给定的函数 \(g(n)\) ,用 \(\Theta(g(n))\) 表示一个函数集合: \[ \Theta(g(n)) = \{f(n) : \text{存在正常数} c_1, c_2 \text{和} n_0 \text{使得对于所有} n \geq n_0, 0 \leq c_1g(n) \leq f(n) \leq c_2g(n)\} \] 直观上就是当 \(n\) 足够大时,函数 \(f(n)\) 的增长率被函数 \(g(n)\) 的增长率所界定
\(\Theta(g(n))\) 要求每个成员 \(f(n)\) 都是渐进非负的,就是 \(n\) 足够大时, \(f(n)\) 的值总是非负的,因此 \(g(n)\) 也应该是渐进非负的
一般来说,对于任意多项式 \(p(n)=\Sigma_{i=0}^da_in^i\) ,其中 \(a_i\) 为常量并且 \(a_d > 0\),我们有 \(p(n) = \Theta(n^d)\)
证明: 点击查看证明
证明:需要找到正常数 \(c_1\)、\(c_2\) 和 \(n_0\) 使得对于所有 \(n \geq n_0\),满足 \(0 \leq c_1n^d \leq p(n) \leq c_2n^d\)
证明下界: \[ p(n)=n^d(a_d + \frac{a_{d-1}}{n}+...+\frac{a_0}{n^d}) \] 令 \(A=|a_{d-1|}+|a_{d-2}|+...+|a_0|\),显然有: \[ | a_{d-1} + \frac{a_{d-2}}{n}+...+\frac{a_0}{n^{d-1}} |\leq | A \] 当 \(n\ge 1\) 时成立,于是有 \[ p(n) \ge n^d(a_d - \frac{A}{n}) \] 由于 \(a_d\) 大于0,所以可以取充分大的 \(n\) 使得 \(a_d - \frac{A}{n} \geq \frac{a_d}{2}\),因此当 \(n \geq n_0\) 时,\(p(n) \geq \frac{a_d}{2}n^d\),证明了下界
证明上界: \[ |p(n)| \leq |a_d|n^d + |a_{d-1}n^{n-1}+...+|a_0| \] 令 \(B=|a_d|+|a_{d-1}|+...+|a_0|\)
这里就有当 \(n\) 足够大时,\(|a_{d-1}n^{n-1}+...+|a_0| \leq |a_d|n^d\),因此当 \(n \geq n_0\) 时,\(p(n) \leq Bn^d\),证明了上界
最终,取 \(c_1=\frac{a_d}{2}\),\(c_2=\Sigma_{i=0}^d|a_d|\),$ n_0 = 2A/a_d $
所以 \(p(n) = \Theta(n^d)\)
\(O\) 符号
对于给定的函数 \(g(n)\),用 \(O(g(n))\) 表示一个函数集合: \[ O(g(n)) = \{f(n) : \text{存在正常数} c \text{和} n_0 \text{使得对于所有} n \geq n_0, 0 \leq f(n) \leq cg(n)\} \] \(\Theta\) 是比 \(O\) 更强的概念,我们有 \(\Theta(g(n))\subseteq O(g(n))\)
\(O\) 给出了一个上界,它表示当 \(n\) 足够大时,函数 \(f(n)\) 的增长率不会超过函数 \(g(n)\) 的增长率的常数倍
\(\Omega\) 符号
对于给定的函数 \(g(n)\),用 \(\Omega(g(n))\) 表示一个函数集合: \[ \Omega(g(n)) = \{f(n) : \text{存在正常数} c \text{和} n_0 \text{使得对于所有} n \geq n_0, 0 \leq cg(n) \leq f(n)\} \] 和 \(O\) 一样, \(\Omega\) 给出了一个下界,它表示当 \(n\) 足够大时,函数 \(f(n)\) 的增长率不会低于函数 \(g(n)\) 的增长率的常数倍
对于任意两个函数 \(f(n)\) 和 \(g(n)\),如果 \(f(n) = O(g(n))\) 且 \(f(n) = \Omega(g(n))\),那么 \(f(n) = \Theta(g(n))\)
\(o\) 符号
我们用 \(o\) 符号来表示一个非渐进紧的上界。对于给定的函数 \(g(n)\),用 \(o(g(n))\) 表示一个函数集合: \[ o(g(n)) = \{f(n) : \text{对于所有正常数} c > 0, \text{存在} n_0 \text{使得对于所有} n \geq n_0, 0 \leq f(n) < cg(n)\} \] 和 \(O\) 记号的主要区别是,\(O\) 记号允许 \(f(n)\) 和 \(g(n)\) 的增长率相同,而 \(o\) 记号要求 \(f(n)\) 的增长率必须严格小于 \(g(n)\) 的增长率
直观上,其实满足这个极限定义式 \[ \lim_{n \to \infty} \frac{f(n)}{g(n)} = 0 \] 这个和数学上的渐进表示其实是一致的
\(\omega\) 符号
我们用 \(\omega\) 符号来表示一个非渐进紧的下界。对于给定的函数 \(g(n)\),用 \(\omega(g(n))\) 表示一个函数集合: \[ \omega(g(n)) = \{f(n) : \text{对于所有正常数} c > 0, \text{存在} n_0 \text{使得对于所有} n \geq n_0, 0 \leq cg(n) < f(n)\} \] 同样的,满足这个极限定义式 \[ \lim_{n \to \infty} \frac{f(n)}{g(n)} = \infty \] 这些增长符号可以和两个实数之间的比较作类比: \[ f(n)=O(g(n)) \text{ 类似于 } a \leq b \\ f(n)=\Omega(g(n)) \text{ 类似于 } a \geq b \\ f(n)=\Theta(g(n)) \text{ 类似于 } a = b \\ f(n)=o(g(n)) \text{ 类似于 } a < b \\ f(n)=\omega(g(n)) \text{ 类似于 } a > b \]
主定理
设一个分治算法将规模 \(n\) 问题分解为 \(a\) 个规模 \(\frac{n}{b}\) 的子问题,合并子问题需要的计算量为 \(f(n)\)
则 \[ T(n)=\begin{cases}O(n^{\log _b(a) })& n^{\log_b(a)} > f(n) \\\\ O(f(n)\log _b(n)) & n^{\log_b(a)}=f(n) \\\\ O(f(n)) & n^{\log_b(a)} < f(n) \end{cases} \]
点击查看证明
容易知道 \[T(n)=\begin{cases}O(1)& n=1 \\\\ aT(\frac{n}{b})+f(n) & n > 1 \end{cases}\]
\(n>1\) 时有 \(T(n)=aT(\frac{n}{b})+f(n)\)
当 \(n=b^m\) 时,\(T(b^m)=aT(b^{m-1})+f(b^{m})\)
则 \(\frac{T(b^m)}{a^m}=\frac{T(b^{m-1})}{a^{m-1}}+\frac{f(b^{m})}{a^m}\)
记 \(R(m)=\frac{T(b^m)}{a^m}\) 则 \(R(m)=R(m-1)+\frac{f(b^{m})}{a^m}\)
则 \(R(m)=\frac{T(b^m)}{a^m}=\sum_{i=1}^m\frac{f(b^{i})}{a^i}+R(0)=\sum_{i=1}^m\frac{f(b^{i})}{a^i}+T(1)\)
则 \(T(b^m)=a^m(\sum_{i=0}^m\frac{f(b^{i})}{a^i}+T(1))\)
由于 \(n=b^m\) 则 \(m=\log _b(n)\)
根据对数性质 \(a^m=n^{\log _b(a)}\)
当 \(n^{\log_b(a)} > f(n)\) 时,\(f(b^i)=O(a^ib^{-i\epsilon})\) \(\sum_{i=0}^mO(b^{-i\epsilon})=O(1)\),\(T(n)=O(n^{\log _b(a)})\)
当 \(n^{\log_b(a)} = f(n)\) 时 \(\sum_{i=0}^m\frac{f(b^{i})}{a^i}=m\),\(T(n)=mf(n)=f(n)\log_b(n)\)
当 \(n^{\log_b(a)} < f(n)\) 时,\(T(n)=\sum_{i=0}^ma^if(\frac{n}{b^i})=O(f(n))\),这里要求\(af(\frac{n}{b})\le cf(n)\)并且满足 \(cf(\frac{n}{b})\le f(n)\),也就是说 \(f(n)\) 的增长率至少要达到 \(n^{\log_b(a)+\epsilon}\) 的程度
需要指出的是,主定理第一种情况不是简单的小于,而是多项式意义上的小于,也就是说,存在一个 \(\epsilon > 0\) 使得 \(f(n) = O(n^{\log_b(a) - \epsilon})\),同样的,第三种情况也是多项式意义上的大于,也就是说,存在一个 \(\epsilon > 0\) 使得 \(f(n) = \Omega(n^{\log_b(a) + \epsilon})\)
算法导论上的结果使用的是 \(\Theta\) ,这里使用 \(O\) 是因为 \(\Theta\) 是一个更强的概念,这里只给出的了上界,若要证明 \(\Theta\) 的版本,需要用类似的方式证明下界 \(\Omega\)
给出一个版本如下:
设递归\(T(n)=aT(n/b)+f(n)\),其中:
- \(a\ge1\)
- \(b>1\)
- \(f(n)\) 为渐近正函数
- \(T(1)=\Theta(1)\)
令\(\alpha=\log_b a\),为简化推导,设\(n=b^m\),记\(S(m)=T(b^m)\)
则 \(S(m)=aS(m-1)+f(b^m)\),\(S(0)=T(1)=\Theta(1)\)
则 \(S(m) = a^m S(0) + \sum_{i=1}^{m} a^{m-i} f(b^i)\)
因此 $ T(bm)=am(T(1)+_{i=1}{m}\frac{f(bi)}{a^i})$
于是有
$ T(n)=n(T(1)+_{i=1}{_b n})$
分析 \(\sum_{i=1}^{\log_b n}\frac{f(b^i)}{a^i}\) 即可:
当 \(f(n) = O(n^{\alpha - \epsilon})\) 时,\(\sum_{i=1}^{\log_b n}\frac{f(b^i)}{a^i} = O(1)\),因此 \(T(n) = O(n^\alpha)\);另一方面,\(T(n)\ge aT(n/b)\),递归展开有\(T(n)\ge a^{\log_b n}T(1)\),因此 \(T(n) = \Omega(n^\alpha)\),所以 \(T(n) = \Theta(n^\alpha)\)
当 \(f(n) = \Theta(n^\alpha)\) 时,\(f(b^i)=\Theta((b^i)^\alpha)=\Theta(a^i)\),因此 \(\sum_{i=1}^{\log_b n}\frac{f(b^i)}{a^i} = \Theta(\log_b n)\),因此 \(T(n) = \Theta(n^\alpha \log_b n)\)
当 \(f(n) = \Omega(n^{\alpha + \epsilon})\) 且满足正则条件 \(af(n/b) \le cf(n)\)(其中 \(c<1\))时:
上界 (\(O\)):由正则条件递推可得 \(a^k f(n/b^k) \le c^k f(n)\)。将递归式展开并改写指标: \[ \begin{aligned} T(n) &= a^{\log_b n}T(1) + \sum_{i=1}^{\log_b n} a^{\log_b n - i} f(b^i) \\ &= \Theta(n^{\alpha}) + \sum_{k=0}^{\log_b n - 1} a^{k} f(n/b^{k}) \\ &\le \Theta(n^{\alpha}) + f(n) \sum_{k=0}^{\log_b n - 1} c^{k} \end{aligned} \] 由于 \(0<c<1\),几何级数 \(\sum_{k=0}^{\log_b n - 1} c^{k}\) 有界,即 \(O(1)\)。又因为 \(f(n) = \Omega(n^{\alpha+\epsilon})\) 增长速度比 \(n^{\alpha}\) 快,所以 \(\Theta(n^{\alpha})\) 项可以被 \(f(n)\) 吸收,故 \(T(n) = O(f(n))\)
下界 (\(\Omega\)):由递推式本身,显然 \(T(n) = aT(n/b) + f(n) \ge f(n)\),因此 \(T(n) = \Omega(f(n))\)。
综合上下界,得 \(T(n) = \Theta(f(n))\)
所以主定理并没有覆盖完所有的情况,例如当 \(f(n) = \Theta(n^{\log_b(a)} \log^k n)\) 时,主定理就无法适用,这时候我们可以使用递归树的方法来分析算法的时间复杂度
事实上,我博客中提出的方法得出的求和公式可以处理很多情况,我们最终得到了 \(T(n)=T(b^m)=a^m(\sum_{i=0}^m\frac{f(b^{i})}{a^i}+T(1))\),\(m =\log_bn\)
这里只需要根据实际的 \(f(n)\) 来分析求和的结果就可以了,例如当 \(f(n) = \Theta(n^{\log_b(a)} \log^k n)\) 时,
主定理的三种情况之间存在 间隙,这个 \(f(n)\) 恰好落在间隙里——它既不满足第二种情况(因为多了 $^k n $),也不多项式地大于 \(n^{\log_b a}\)
\(f(b^i)=\Theta(b^{i\times\log_b(a)}\log^k(b^i))=\Theta(i^ka^i\log^kb)\) \[ T(n)=a^m\sum_{i=0}^m\frac{f(b^{i})}{a^i}\\ =a^m\sum_{i=0}^m\frac{\Theta(i^ka^i)}{a^i}\\ =a^m\sum_{i=0}^m\Theta(i^k)\\ =a^m\Theta(\sum_{i=0}^mi^k)\\ =a^m\Theta(\int_1^mx^k dx)\\ =a^m\Theta(m^{k+1})\\ =\Theta(n^{\log_b(a)}\log^{k+1}n) \]
| \(f(n)\) 的形式 | \(g(i) = \frac{f(b^i)}{a^i}\) | \(\sum_{i=0}^m g(i)\) | 估计方法 |
|---|---|---|---|
| \(n^{\log_b a - \epsilon}\) | \(b^{-i\epsilon}\) | \(\Theta(1)\) | 几何级数(公比 < 1) |
| \(n^{\log_b a}\) | \(1\) | \(\Theta(m)\) | 等差数列 |
| \(n^{\log_b a} \log^k n\) | \(i^k\) | \(\Theta(m^{k+1})\) | 积分近似 |
| \(\frac{n^{\log_b a}} {\log n}\) | \(\frac{1}{i}\) | \(\Theta(\log m)\) | 调和级数 |
| \(n^{\log_b a} \cdot 2^{\sqrt{\log n}}\) | \(2^{\sqrt{i \log b}}\) | 需要专门分析 | 复杂情况 |
| \(n^{\log_b a + \epsilon}\) | \(b^{i\epsilon}\) | \(\Theta(b^{m\epsilon})\) | 几何级数(公比 > 1) |
目前递归项只有一项,如果递归项有多项呢,这个时候就可以使用 Akra-Bazzi 定理来分析了
Akra-Bazzi 定理
设 \(T(n)\) 是满足以下递归关系的函数: \[ T(n) = \begin{cases} \Theta(1) & n \leq n_0 \\ \sum_{i=1}^k a_i T\left(b_in\right) + f(n) & n > n_0 \end{cases} \] 其中 \(a_i > 0\) 是常数,\(0 < b_i < 1\) 是常数,\(f(n)\) 是渐近正函数,满足多项式增长条件,\(n_0\) 是常数
定义(多项式增长条件):称 $f(x) $ 满足多项式增长条件,若存在正常数 $ c_1, c_2 $,使得对所有 $x $,所有 $1 i k $,以及所有 $u \(,都有\)$ c_1 f(x) f(u) c_2 f(x) $$
如果存在一个实数 \(p\) 满足以下方程: \[ \sum_{i=1}^k a_i b_i^p = 1 \] 那么就有: \[ T(n) = \Theta\left(n^p \left(1 + \int_1^n \frac{f(u)}{u^{p+1}} du\right)\right) \]
\(p\) 是为了平衡递归树各层的“权重”,使得变换后的 \(A(n)\) 的递归式系数之和为1,从而让后续的迭代展开成为一个“概率平均”的过程
多项式增长条件保证了 \(f(n)\) 在不同规模的子问题上的值不会有过大的波动,这样在分析递归树时,我们可以将 \(f(n)\) 视为在同一数量级上
点击查看证明
记 \(A(n)=\frac{T(n)}{n^p}\),递归式两端同时除以 \(n^p\) 得到 \[ \frac{T(n)}{n^p} = \sum_{i=1}^k a_i \frac{T(b_in)}{n^p} + \frac{f(n)}{n^p}\\ = \sum_{i=1}^k a_i b_i^p \frac{T(b_in)}{(b_in)^p} + \frac{f(n)}{n^p}\\ \] 也就是 \[ A(n) = \sum_{i=1}^k a_i b_i^p A(b_in) + \frac{f(n)}{n^p} \] 由于 \(p\) 满足 \(\sum_{i=1}^k a_i b_i^p = 1\),所以 \(A(n) = \sum_{i=1}^k a_i b_i^p A(b_in) + \frac{f(n)}{n^p}\) 可以看成是一个卷积式的递归关系
我们设 \(w_i=a_ib_i^p\),那么有 \(\sum_{i=1}^k w_i = 1\),因此 \(A(n) = \sum_{i=1}^k w_i A(b_in) + \frac{f(n)}{n^p}\)
我们可以通过迭代展开来求解 \(A(n)\),首先将 \(A(n)\) 展开一次: \[ A(n) = \sum_{i=1}^k w_i A(b_in) + \frac{f(n)}{n^p} \] 继续展开 \(A(b_in)\): \[ A(n) = \sum_{i=1}^k w_i \left( \sum_{j=1}^k w_j A(b_j b_i n) + \frac{f(b_in)}{(b_in)^p} \right) + \frac{f(n)}{n^p} \] 展开 \(t\) 次后得到 \[ A(n)=\sum_{|s|=t} W(s)A(b_s n)+\sum_{j=0}^{t-1}\sum_{|s|=j}W(s)\frac{f(b_s n)}{(b_s n)^p} \] 其中
- \(s\) 是一个长度为 \(t\) 的序列,\(|s|\) 表示序列的长度
- \(b_s=b_{i_1}\cdots b_{i_j}\),也就是 \(s\) 中元素对应的 \(b_i\) 的乘积
- \(W(s)=w_{i_1}\cdots w_{i_j}\),也就是 \(s\) 中元素对应的 \(w_i\) 的乘积
当递归进行到常数 \(\Theta(1)\) 时终止,由于 \(b_i<1\),所以存在 \(c\) 为常数使得 \(b_i \leq c < 1\),因此 \(b_s \leq c^t\),当 \(t\) 足够大时,\(b_s n \leq n_0\),此时 \(A(b_s n) = \Theta(1)\)
因此第一个项的贡献是 \(\Theta(\sum_{|s|=t} W(s))\),又由于 \(\sum_{|s|=t} W(s) = (\sum_{i=1}^k w_i)^t = 1^t = 1\),所以 \[ A(n) = \Theta(1) + \sum_{j=0}^{t-1}\sum_{|s|=j}W(s)\frac{f(b_s n)}{(b_s n)^p} \] 分析第二项,固定 \(j\),所有 \(b_sn\) 大概在 \(n\Theta(\beta^j)\) 这个量级,这是由于对所有长度为 \(j\) 的路径 \(s\),\(b_s\) 的取值范围在 \([\beta_{\min}^j, \beta^j]\) 之间,因此所有 \(b_s n\) 都落在区间 \([\beta_{\min}^j n,, \beta^j n]\) 内,其中 \(\beta = \max b_i\)
这里需要用到多项式增长条件:存在正常数 $ c_1, c_2 $,使得对所有 \(u \in [b_i x, x]\) 都有 \(c_1 f(x) \leq f(u) \leq c_2 f(x)\)。这个条件保证了 \(\frac{f(u)}{u^p}\) 在 \([\beta_{\min}^j n, \beta^j n]\) 这个区间上的所有值都处于同一数量级,记代表点为 \(u_j = \beta^j n\),则对任意长度为 \(j\) 的路径 \(s\),有 \[ \frac{f(b_s n)}{(b_s n)^p} = \Theta\left(\frac{f(u_j)}{u_j^p}\right) \]
由于 \(\sum_{|s|=t} W(s) = (\sum_{i=1}^k w_i)^t = 1^t = 1\),所以贡献近似为 \(\Theta(\frac{f(u_j)}{u_j^p})\),其中 \(u_j = n\Theta(\beta^j)\),因此 \[ A(n) = \Theta(1) + \sum_{j=0}^{t-1}\Theta(\frac{f(u_j)}{u_j^p}) \] 下面将这个求和转化为积分。令 \(h(u) = \frac{f(u)}{u^{p+1}}\),注意到 \(u_{j+1} = \beta u_j\),所以
\(u_j - u_{j+1} = (1-\beta)u_j\),所以 \(h(u_j)(u_j-u_{j+1}) = \frac{f(u_j)}{u_j^{p+1}} (1-\beta)u_j = (1-\beta) \frac{f(u_j)}{u_j^p}\),所以两者确实只差一个常数因子,因此 \[ \frac{f(u_j)}{u_j^p} = h(u_j) \cdot u_j = h(u_j) \cdot \frac{u_j - u_{j+1}}{1 - \beta} = \Theta\left(h(u_j)(u_j - u_{j+1})\right) \]
因此 \[ \sum_{j=0}^{t-1}\Theta\left(\frac{f(u_j)}{u_j^p}\right) = \Theta\left(\sum_{j=0}^{t-1} h(u_j)(u_j - u_{j+1})\right) \]
这是一个 Riemann 和。由于 \(u_{j+1} = \beta u_j\),每个小区间 \([u_{j+1}, u_j]\) 上 \(h(u)\) 的值由多项式增长条件保证在同一数量级,所以 Riemann 和与积分只差常数倍,也就是 \[ \Theta\left(\sum_{j=0}^{t-1} h(u_j)(u_j - u_{j+1})\right) = \Theta\left(\int_{u_t}^{u_0} h(u), du\right) = \Theta\left(\int_{u_t}^{n} \frac{f(u)}{u^{p+1}}, du\right) \]
这里 \(u_0 = n\),\(u_t = \beta^t n\)。由 \(\beta^t \leq c^t\)
由于 \(c<1\),所以 \(u_t = \beta^t n \leq c^t n\),当 \(t = \Theta(\log n)\) 时,\(u_t = \Theta(1)\),因此 \(t = \Theta(\log n)\)
所以 \[ \int_{u_t}^{n} \frac{f(u)}{u^{p+1}}, du = \Theta\left(\int_1^n \frac{f(u)}{u^{p+1}}, du\right) \]
综合起来 \[ A(n) = \Theta\left(1 + \int_1^n \frac{f(u)}{u^{p+1}}, du\right) \]
因此 \[ T(n) = n^p A(n) = \Theta\left(n^p \left(1 + \int_1^n \frac{f(u)}{u^{p+1}}, du\right)\right) \]
这个时候反过来看推导主定理时候的结果:
\(T(n)=T(b^m)=T(b^m)=a^m(\sum_{i=0}^m\frac{f(b^{i})}{a^i}+T(1))\),\(m =\log_bn\)
这个时候其实就是 Akra-Bazzi 定理的离散版本,也就是最后不估计求和的递推式只有一项的结果
换句话说,主定理只是 Akra-Bazzi 定理的一个特例
另外,需要注意一下在定理证明时的一个思想:
展开表达式预估什么时候到 \(\Theta(1)\) ,这个思想其实才是所有定理的核心思想,例如在主定理的证明中,我们通过分析 \(b_s n\) 的大小来预估什么时候到 \(\Theta(1)\),在 Akra-Bazzi 定理的证明中,我们通过分析 \(b_i\) 的大小来预估什么时候到 \(\Theta(1)\)
这个思想也可以处理这两个定理覆盖不到的非线性缩小的递归,这个思想其实也是递归树的核心思想
递归树、代入法和非线性缩放递归
例如 \(T(n)=2T(\sqrt n)+\Theta(\log n)\) 这种莫名奇妙的递归关系,主定理和 Akra-Bazzi 定理都无法处理
这类非线性缩小的递归,都会用到我们证明定理时用到的两个核心思想:
- 递归深度分析
- 求和分析
递归树
递归树的每一层表示递归调用的一层,树的每个节点表示一个递归调用的子问题的代价
可以将树中的每层代价求和,得到每层的代价,最后将所有层的代价求和,得到整个递归的代价
我们用算法导论中的例子来介绍递归树
\(T(n)=3T(\frac{n}{4})+cn^2\)
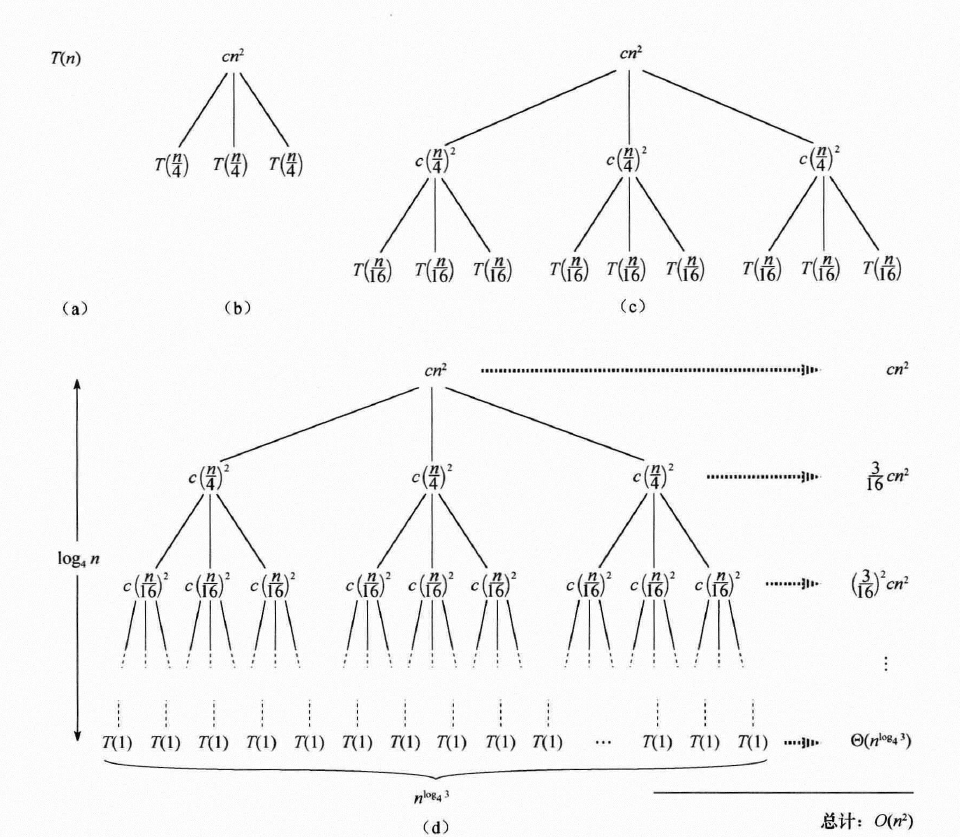
可以看到,这种算法其实就是我们证明上述两个定理的核心思想,以 Akra-Bazzi 定理为例,\(t\) 就是递归深度,陆续带入递推式就是最终的求和分析
我们先对这个东西进行分析:
递归树的深度为 \(\log_4 n\),因为每次递归调用都会将问题规模缩小为原来的一半,所以递归树的深度是 \(\log_4 n\)
每层的代价为 \(3^i c (\frac{n}{4^i})^2\),因为每个节点的代价为 \(cn^2\),每次递归调用都会产生 \(3\) 个子问题,所以每层的代价为 \(3^i c (\frac{n}{4^i})^2\)
每层的代价为 \(3^i c (\frac{n}{4^i})^2\),最后一层 \(\Theta(1)\) 贡献了 \(\Theta(n^{\log_43})\) 所以总的代价为 \(\sum_{i=0}^{\log_4 n} 3^i c (\frac{n}{4^i})^2+\Theta(n^{\log_43})\)
直接暴力放缩 \[ T(n)=\sum_{i=0}^{\log_4 n} 3^i c (\frac{n}{4^i})^2+\Theta(n^{\log_43}) \\ < \sum_{i=0}^{\infty} 3^i c (\frac{n}{4^i})^2+\Theta(n^{\log_43})\\ = \sum_{i=0}^{\infty} 3^i c \frac{n^2}{4^{2i}}+\Theta(n^{\log_43})\\ = cn^2\sum_{i=0}^{\infty} (\frac{3}{16})^i+\Theta(n^{\log_43})\\ = O(n^2) \] 我们得到了一个上界,那我们怎么验证这个上界是紧的呢
代入法
代入法其实也是求递归关系的方法,他的流程是:
- 猜测解的形式
- 用数学归纳法求出解的常数,并证明解是正确的
由此来看,代入法其实更适合来验证答案是否正确,恰好,递归树法给了我们一个上界,我们可以用代入法来验证这个上界是否正确
代入法的步骤
先介绍代入法的步骤:
我们以 \(T(n)=2T(\frac{n}{2})+n\) 为例
- 猜测解为 \(O(n \lg n)\)
- 代入
选择常数 \(c>0\),可有 \(T(n)\le cn\lg n\),首先假定这个上界对所有 \(m<n\) 都成立,当 \(m = \frac{n}{2}\) 时,\(T(\frac{n}{2})\le c\frac{n}{2}\lg \frac{n}{2}\)
带入有 \[ T(n) = 2T(\frac{n}{2})+n \\ \le 2c\frac{n}{2}\lg \frac{n}{2}+n\\ \le cn\lg\frac{n}{2}+n \\ =cn\lg n - cn+n\\ \le cn\lg n \] 最后,只要 \(c\ge 1\) 就可以了,所以 \(T(n)=O(n \lg n)\)
代入法的特殊情形
有时候可能猜出了递归式的渐进界,但是归纳失败了,例如 \(T(n)=2T(\frac{n}{2})+1\),我们猜测 \(T(n)=O(n)\)
选择常数 \(c>0\),可有 \(T(n)\le cn\),首先假定这个上界对所有 \(m<n\) 都成立,当 \(m = \frac{n}{2}\) 时,\(T(\frac{n}{2})\le c\frac{n}{2}\),则 \(T(n)\le cn+1\)
我们可以看到,\(T(n)\le cn+1\) 这个式子是无法满足 \(T(n)\le cn\) 的,所以归纳失败了,从直觉上,这个界应该是正确的,所以我们可以对 \(T(n)\le cn\) 进行一个微调,例如 \(T(n)\le cn-d\),其中 \(d\) 是一个常数,带入有 $$ T(n) = 2T()+1 \ (c-d)+1 \
= cn - 2d + 1 \ cn - d $$ 只要 \(d \ge 1\),就可以满足 \(T(n)\le cn-d\),所以 \(T(n)=O(n)\)
一个误区
最终不能得到 \(O(n)\) 结果的情况:
如果证明到 \(T(n)\le cn+n\),我们不能得出 \(T(n)=O(n)\) 的结论,因为 \(T(n)\le cn+n\) 这个式子是无法满足 \(T(n)\le cn\) 的,需要显式的证明出归纳假设,这里的 \(c\) 也不能吸收掉 \(n\),所以我们无法得出 \(T(n)=O(n)\) 的结论
课堂例子:低阶项有时不能直接丢
考虑 \[ T(n)=4T(n/2)+n \]
如果先猜 \(T(n)=O(n^3)\),代入很容易成功: \[ T(n)\le 4c(n/2)^3+n=\frac{c}{2}n^3+n\le cn^3 \] 只要 \(n\) 足够大、\(c\) 选得足够大即可。但这个上界明显偏松。
继续猜 \(T(n)=O(n^2)\),如果直接用归纳假设 \(T(k)\le ck^2\),会得到 \[ T(n)\le 4c(n/2)^2+n=cn^2+n \] 这里不能把最后的 \(+n\) 直接吸收到 \(cn^2\) 中,因为归纳目标是精确回到 \(T(n)\le cn^2\)。
解决方法是加强归纳假设,例如猜 \[ T(k)\le ck^2-dk \] 则 \[ T(n)\le 4(c(n/2)^2-d(n/2))+n=cn^2-2dn+n \] 只要 \(d\ge 1\),就有 \[ cn^2-2dn+n\le cn^2-dn \] 因此 \(T(n)=O(n^2)\)。另一方面由递归式本身也可以得到 \(\Omega(n^2)\),所以 \(T(n)=\Theta(n^2)\)。
代入法验证递归树结果
回到之前递归树得到的一个结果
\(T(n)=3T(\frac{n}{4})+cn^2\)
我们猜测 \(T(n)=O(n^2)\),选择常数 \(c>0\),可有 \(T(n)\le cn^2\),首先假定这个上界对所有 \(m<n\) 都成立,当 \(m = \frac{n}{4}\) 时,\(T(\frac{n}{4})\le c\frac{n^2}{16}\)
带入有 \[ T(n) = 3T(\frac{n}{4})+cn^2 \\ \le 3c\frac{n^2}{16}+cn^2 \\ \le dn^2 \] 当 \(d\ge \frac{16}{13}c\) 时,\(T(n)\le dn^2\) 成立,所以 \(T(n)=O(n^2)\)
非线性缩放递归
回到了我们的主题,现在可以用递归树来分析非线性递归了
例如 \(T(n)=2T(\sqrt n)+\Theta(\log n)\)
首先每个子问题的规模是 \(\sqrt n\),考虑 \(t\) 次后规模为 \(\Theta(1)\),也就是 \(n^{2^t}=\Theta(1)\),所以 \(t=\Theta(\log \log n)\)
也就是说递归树的深度为 \(\Theta(\log \log n)\)
每一层,第 \(i\) 层的代价为 \(2^i \Theta(\log n^{\frac{1}{2^i}})=\Theta(\log n)\),所以总的代价为 \(\sum_{i=0}^{\Theta(\log \log n)} \Theta(\log n) = \Theta(\log n \log \log n)\)
一般形式:\(T(n)=T(g(n))+f(n)\)
这里的所有 \(g\) 都是非线性的
递归树深度:满足 \(g^{(k)}(n)=\Theta(1)\) 的 \(k\)
于是 \[ T(n)=\sum_{i=0}^{k-1} f(g^{(i)}(n)) + \Theta(1) \]
一般形式:\(T(n)=\sum_{i=1}^{r}T(g_i(n))+f(n)\)
这里的所有 \(g\) 都是非线性的
设 \(g(n)=\max_{1\le i \le r}g_i(n)\)
递归树深度:满足 \(g^{(k)}(n)=\Theta(1)\) 的 \(k\)
递归第 \(j\) 层 最多有 \(r^j\) 个节点,每个节点的代价为 \(f(g^{(j)}(n))\),所以第 \(j\) 层的总代价为 \(r^j f(g^{(j)}(n))\)
于是有上界 \[ O(\sum_{i=0}^{k-1} r^i f(g^{(i)}(n)) + \Theta(1)) \] 另一方面,递归树至少存在一条路径 \(n_0=n,\quad n_{j+1}=g(n_j)\)
所以有下界 \[ \Omega(\sum_{i=0}^{k-1} f(g^{(i)}(n)) + \Theta(1)) \]
综上 \[ \sum_{i=0}^{k-1} f(g^{(i)}(n)) \le T(n) \le \sum_{i=0}^{k-1} r^i f(g^{(i)}(n)) \] 进一步的,如果 \(g_i(n)=\Theta(g(n))\) \[ T(n)=\Theta(\sum_{i=0}^{k-1} r^i f(g^{(i)}(n)) + \Theta(1)) \]
最后的例子
我们最后用一个例子作为总结:
\(T(n)=2(\log n)+3(n^{\frac{1}{3}})+n^2\)
每个节点产生 2 个 \(\log\) 子问题和 3 个 \(n^{\frac{1}{3}}\) 子问题
取主导分支 \(g(n) = n^{1/3}\),递归深度满足 \(n^{(1/3)^k} = \Theta(1)\),即 \(k = \Theta(\log\log n)\)
第 \(i\) 层最多 \((2+3)^i = 5^i\) 个节点(两种子问题合并考虑),每个节点代价为 \(f(g^{(i)}(n)) = (n^{(1/3)^i})^2 = n^{2/3^i}\),所以
\[T(n) = \sum_{i=0}^{\Theta(\log\log n)} 5^i \cdot n^{2/3^i} + \Theta(1)\]
第 \(i=0\) 项为 \(n^2\),对 \(i \geq 1\),\(n^{2/3^i}\) 衰减极快,具体地,当 \(3^i > \log n\) 时 \(n^{2/3^i} = O(1)\),此时 \(5^i \cdot n^{2/3^i} = O(5^{\log\log n}) = O((\log n)^{\log 5})\),远小于 \(n^2\),所以整个求和由首项主导
综上,\(T(n)=O(n^2)\)